
AI玩《毁灭战士》集体翻车:GPT-4o、Claude、Gemini在第一关已全军覆没
为了降低入门门槛,该研究团队还贴心地提供了一个基础版的“游戏AI代理(VideoGameAgent)”,这个代理支持基础的“记忆能力”(比如记住之前画面),还能和现在主流的大语言模型 API(比如 GPT、Claude、Gemini、DeepSeek 等)直接对接,借助 LiteLLM 实现无缝调用。最近一个更大的问题是,能不能解决语言密集型的游戏。专注于真实的视频游戏,采用一组固定且有挑战性的游

作者 | Alex Zhang、Ofir Press
翻译 | 苏宓
出品 | CSDN(ID:CSDNnews)
让 GPT-4o、Claude Sonnet 3.7、Gemini 2.5 Pro 和 Gemini 2.0 Flash 一起上阵挑战《Doom II》(默认难度),会有什么样的结果?它们能通关吗?
谁能想到,所有模型都使用了相同的输入提示,但结果嘛……只能说“各显神通”,虽然大家都在努力“冲关”,但没有一个能成功通过第一关。
这是普林斯顿大学的研究人员最新发现的结果。该团队近日发布了一个有趣的研究预览项目:VideoGameBench——这是一个专门为视觉语言模型(VLM)设计的游戏挑战基准,测试它们能否实时通关来自掌机和 PC 平台的 20 款热门游戏。
其中研究人员还引入了一个轻量版本 VideoGameBench-Lite,它的特别之处在于:在模型“思考”时会自动暂停游戏,从而绕过了当前 VLM 推理延迟过高的瓶颈,为模型提供一个更公平的发挥空间。
与传统游戏 AI 不同,VideoGameBench 不依赖模型对游戏规则的预训练或硬编码提示。研究人员强调,他们更关注的是:模型是否可以仅凭游戏画面,就完成从零到通关的全过程。为此,他们在研究预览中开源了相关代码、评测框架,并分享了初步实验结果。这个基准测试究竟是什么样的,我们不妨来看看。
-
GitHub 地址:https://github.com/alexzhang13/VideoGameBench

视觉语言模型基准测试来了
研究人员指出,语言模型(LM)已经被证明能解决非常复杂的推理任务,比如数学题和编程问题。对普通人来说,这些任务都挺难的,因为它们需要很多预备知识和模式识别能力。但有趣的是,虽然人类可以玩通视频游戏,我们至今还没见过哪怕是最先进的语言模型或视觉语言模型能完整通关《Doom》或者《宝可梦》这种游戏。所以很多研究干脆就只关注一些比较简单的小游戏,或者是自己写的小型程序游戏。
要想真正通关一款真实的视频游戏,模型不仅得能短期和长期推理,还得有空间理解能力和直觉(比如你要知道,找一把钥匙去开门,这种“先找钥匙再过门”的常识)。过去,AI 想在游戏中表现好,通常是专门针对某一款游戏训练的,需要海量的探索时间或者专家操作记录。相比之下,视觉语言模型是一种新思路:它们可能可以靠理解图像+语言提示,在没玩过的游戏中也取得不错成绩。
因此,在未来完整版的 VideoGameBench 中,研究人员还计划加入一组“保密游戏”来作为评测套件,用来进一步测试模型在新游戏上的真实能力表现。
这是 VideoGameBench 中一部分示例游戏,VideoGameAgent 正在游玩这些游戏(思考过程和动作展示在画面旁边)。每款游戏的机制、玩法和画面风格都各不相同。

VideoGameBench 框架和环境
在这次研究预览中,VideoGameBench 提供了一个统一的测试平台,允许 AI 智能体在一个环境中同时运行他们挑选的 20 款经典游戏,涵盖了 Game Boy 和 MS-DOS 两大平台。
为了让模型能顺利地“玩游戏”,这个测试框架封装了底层复杂的模拟器部分(目前支持通过 PyBoy 运行 Game Boy 游戏,通过 DOSBOX 运行 MS-DOS 游戏),让使用者不用关心复杂的底层操作,而只需要专注于输入和输出的交互,就能控制智能体玩游戏:
1. 观察内容:就是游戏画面本身,作为一张图片传递给模型。模型就像是人类玩家一样,看着游戏画面来判断下一步要干什么。
2. 操作接口:框架提供了一个虚拟“手柄”,模型可以选择按下一个键(比如“空格键”)、执行一串动作(比如连续按两次“A”再按“开始”键),或者是“按住某个键一段时间再松开”,就像真实玩家那样操作。
3. 游戏是否通关的反馈:系统会告诉模型它有没有成功通关某个游戏。
需要特别说明的是,这个测试框架只给模型提供游戏画面,不会额外提供像游戏内的文字提示、地图信息、或者什么敌人在哪的“外挂式”信息。这和 DeepMind 训练《星际争霸2》的 AI(AlphaStar)那种方式不同,后者是靠读取游戏的内部数据来操作的。而这里的模型则需要靠“看图”来通关,挑战更大。
目前,这只是一个早期版本的研究预览,研究人员提供了一个简化的基础实现,方便开发者开箱即用,也可以自己修改、拓展测试自己的模型。此外,他们还在开发更多适配不同模型的高级功能,这些会在之后的正式论文发布时一并推出。
为了降低入门门槛,该研究团队还贴心地提供了一个基础版的“游戏AI代理(VideoGameAgent)”,这个代理支持基础的“记忆能力”(比如记住之前画面),还能和现在主流的大语言模型 API(比如 GPT、Claude、Gemini、DeepSeek 等)直接对接,借助 LiteLLM 实现无缝调用。
你可以在下图中看到游戏画面和用户界面是并排显示的:
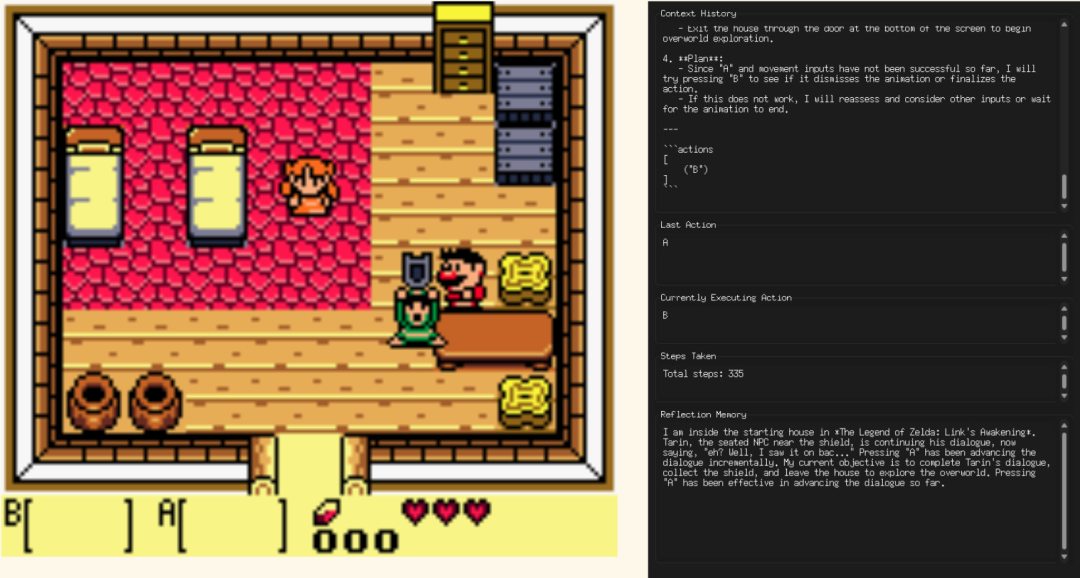
测试环境配备了一些简单的用户界面代码,用于在每一步中记录智能体的思考过程、执行的动作以及记忆内容。
目前,该基准测试主要聚焦在早期的 Game Boy 和经典的 MS-DOS 游戏上,原因有两点:一是这些游戏在视觉提示上相对现代游戏要简单得多;二是它们涵盖了手柄操作以及鼠标+键盘操作两种模式,这对视觉语言模型(VLM)在空间理解能力上的挑战,与基于文本或终端的游戏操作完全不同。
关于评估进度和游戏完成情况,由于模拟器和游戏引擎本身并不会提供“游戏是否通关”的专用反馈信号,研究团队开发了一套机制,用于判断智能体是否成功完成游戏任务。这套机制通过对比智能体当前画面与预设的“通关参考截图”来识别游戏是否完成。此外,这种方法还适用于检测用户自定义的“阶段性目标完成情况”,比如在《魔兽争霸 II》这类游戏中,仅评估某一特定战役(如兽人战役)的完成情况,这对于衡量智能体的阶段性进展或部分任务通关表现非常有价值。

VideoGameBench:游戏列表
该研究团队在挑选游戏时,综合考虑了游戏的相对难度和玩法多样性,并在下方列表中对这些特性进行了简要标注。部分游戏要求智能体完成整个单人模式,例如《超级马里奥大陆》和《塞尔达传说:织梦岛》;而另一些游戏由于流程较长,仅需完成其中一个战役或单局游戏,例如《文明 1》。此外,出于世界探索元素足够丰富的考虑,团队还在某些游戏中纳入了续作,以增强基准测试的多样性和挑战性。

以下是这 20 款游戏的完整名单,分为两个平台:MS-DOS(电脑游戏)和 Game Boy(掌机游戏):
MS-DOS 平台游戏:
-
Doom(毁灭战士):3D 第一人称射击游戏
-
Doom II(毁灭战士2):3D 第一人称射击游戏
-
Quake(雷神之锤):3D 第一人称射击游戏
-
文明1(Sid Meier’s Civilization 1):2D 策略类、回合制
-
魔兽争霸2:黑潮(Warcraft II: Tides of Darkness):2.5D 策略类,这次只打“兽人战役”
-
俄勒冈之旅豪华版(Oregon Trail Deluxe,1992年):2D 策略类、回合制
-
X-COM 外星人防御(X-COM UFO Defense):2D 策略类
-
不可思议的机器(The Incredible Machine,1993年):2D 解谜类
-
波斯王子(Prince of Persia):2D 横版动作平台
-
极品飞车初代(The Need for Speed):3D 赛车类
-
帝国时代1(Age of Empires,1997年):2D 策略类
Game Boy / Game Boy Color 掌机游戏:
-
Pokemon Red:2D 网格地图、回合制战斗
-
Pokemon Crystal:2D 网格地图、回合制战斗
-
塞尔达传说:织梦岛 DX 版(Legend of Zelda: Link’s Awakening DX):2D 开放世界冒险
-
超级马里奥大陆(Super Mario Land):2D 横版动作平台
-
Kirby’s Dream Land DX Mod:2D 横版动作平台
-
Mega Man: Dr. Wily’s Revenge:2D 横版动作平台
-
Donkey Kong Land 2:2D 横版动作平台
-
Castlevania Adventure:2D 横版动作平台
-
Scooby-Doo! - Classic Creep Capers:2D 侦探冒险类

VideoGameBench-Lite:让智能体有时间思考
据研究团队观察,目前最先进的视觉语言模型(VLM)在玩视频游戏时面临一个明显的挑战:推理延迟过高。具体来说,当智能体截取游戏画面并向大模型询问接下来的动作时,等模型返回结果时,游戏场景往往已经发生了显著变化,导致原本建议的动作已不再适用。比如,截图时一个敌人正向智能体开火,而等到模型给出回应时,这个敌人可能已经移动到了智能体正前方。
为了解决这一问题,研究人员在 VideoGameBench 的基础上推出了轻量级版本 VideoGameBench-Lite。这个版本为模型“留出思考时间”,在游戏流程上做出适当调整,让大模型有充足时间推理再做出反应。
研究团队的智能体(基于 GPT-4o)在 VideoGameBench-Lite 中游玩《毁灭战士 II》(最低难度)。为了让智能体有时间思考,环境在其推理时会暂停游戏。该智能体成功击败了敌人,并能够在关卡中自由移动。
VideoGameBench-Lite 所涵盖的部分游戏如下:
-
Doom II:3D 射击游戏
-
Quake:3D 射击游戏
-
波斯王子(Prince of Persia):2D 平台跳跃类游戏
-
塞尔达传说:梦见岛(Game Boy 彩色版 DX):2D 开放世界冒险
-
超级马里奥大陆(Super Mario Land):2D 平台跳跃游戏
-
星之卡比:梦之地(Game Boy 彩色 DX Mod):2D 平台跳跃游戏

初步观察:AI 想通关游戏,还差得远
研究人员在跑完几款经典游戏之后发现,目前的视觉语言大模型(VLM)扮演的游戏 AI 还远远没有能力通关完整游戏,甚至连大多数游戏的第一关都打不过。虽然有些有趣的进展,比如 AI 在《星之卡比》中成功打到了第一个小 Boss,已经算是“了不起的进步”,但整体来看,大多数时候 AI 的表现还处在“尝试理解游戏”的阶段。
研究团队在这一部分没有进行非常严谨的量化实验,而是通过一些“定性观察”来分享现阶段 AI 玩游戏时遇到的问题。所有测试使用的是一个基础版的 VideoGameAgent,这个代理模型使用了 ReAct 思维链框架,能记住连续 5 到 10 帧的游戏画面,并根据这些画面发出一系列按键操作或鼠标动作。
思路混乱、目标感不强
在之前的一些研究中,确实有成功用大语言模型来做游戏规划的案例,也有模型能玩文字类游戏。但在视觉+语言的组合场景下,AI 往往会错误解读画面中的信息,这就会导致它做出奇怪的行为,比如把已经死掉的敌人当成活的,然后一直对着他们开枪浪费子弹。
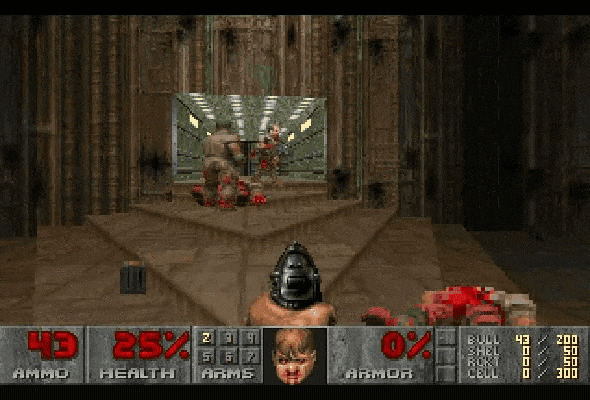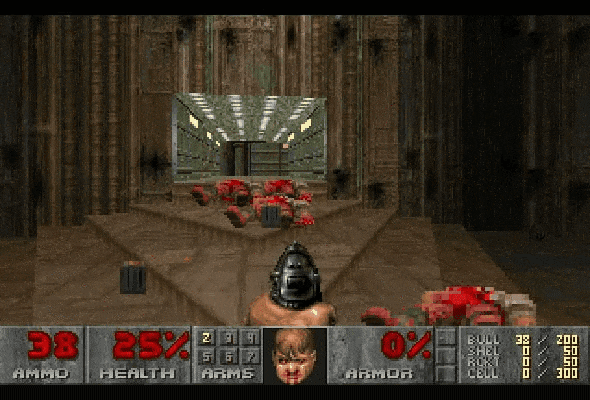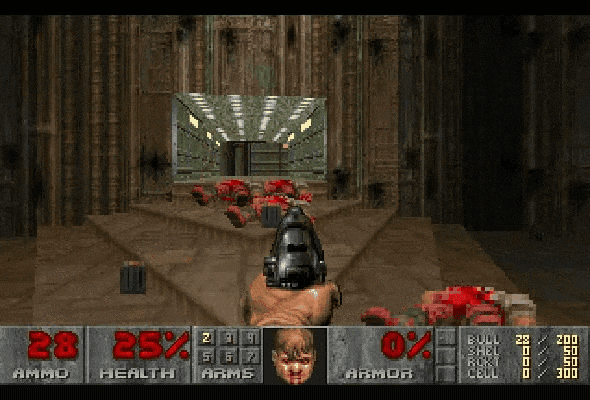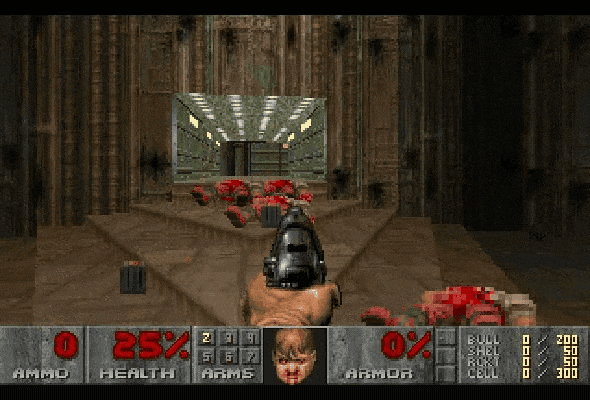
Claude Sonnet 3.7 在玩《毁灭战士2》时,连续把死掉的敌人误判为还活着的,导致子弹全打空,影响了后续的战术决策。
什么叫“一次动作”?AI 搞不清楚
还有一个很现实的问题:大模型的“思考”速度跟不上游戏节奏。比如 GPT-4o 在玩《超级马里奥大陆》时,每看一帧画面就需要3 到 5 秒才能给出下一个动作。但等它给出决策时,游戏早已经继续运行了几秒,敌人早冲过来了,结果就是 AI 还没反应过来就连续被同一个小怪干掉。
这就引发了一个值得研究的问题:对 AI 来说,“一个动作”到底是什么? 是按一下键?还是连续按几下?或者是执行一段简单的程序?这会极大影响游戏表现。
鼠标和键盘的精度也成问题
目前所有主流模型(包括 GPT-4o、Claude Sonnet 3.7、Gemini 2.5 Pro)都普遍存在一个问题:控制鼠标的准确性太差。比如在玩《魔兽争霸2》和《文明1》这种依赖鼠标操作的策略游戏时,AI 频繁点错位置。最离谱的是,它想点“新游戏”,结果老是点成“加载游戏”,一直卡在菜单界面。

GPT-4o 玩《魔兽争霸2》时鼠标定位不准,总是点错按钮,无法顺利开始游戏。
游戏机制太“反人类”,AI 不知道怎么玩
有些游戏机制对人类玩家来说再自然不过,但对 AI 来说如果没有提前说明,它压根不会自己发现。
比如在《星之卡比》里,卡比可以吞掉敌人的炸弹,然后变出特殊能力打 Boss——这是游戏的核心玩法之一。但 GPT-4o 完全不知道这回事,打到了小 Boss 也不会用技能,硬刚半天还打不过。

GPT-4o 在《星之卡比》中打到小 Boss,但不理解可以复制能力的机制,错失击败敌人的最佳方式。

回顾以往研究:AI 玩游戏已经不是新鲜事,但难点还在
游戏中的 RL
尽管现在大模型(尤其是视觉语言模型 VLM)玩游戏还不够聪明,但这事其实早在很久以前就有人研究过,特别是在强化学习(RL)领域。
强化学习早就把很多游戏“打通关”了。比如,RL 在十年前就能玩转 Atari 街机游戏;DeepMind 的 AlphaGo 更是在围棋上战胜了人类世界冠军,虽然围棋的规则比较明确、操作也都是一步一步走棋,不是那种实时操作的复杂游戏。
很多人曾以为视频游戏更复杂,AI 很难搞定,但 DeepMind 的 AlphaStar(打星际争霸)和 OpenAI Five(打刀塔2)都证明了:只要游戏环境“特征化”得好,电子游戏也可以被 AI 玩得比人还强。即便是三维游戏这种特征提取很难的环境,像 Dreamer 这样的项目也在努力用 RL 去玩 Minecraft。
最近一个更大的问题是,能不能解决语言密集型的游戏。这些方法通过使用语言模型来替代强化学习中的一些模块,比如价值函数。一个很有意思的例子是,新的 AI 智能体在《精灵宝可梦对战》这款回合制游戏中已经达到了和人类玩家竞争的水平。另一个例子是 CICERO 智能体,它用于多人策略游戏《外交》。
纯视觉语言模型(VLMs)和语言模型(LMs)玩游戏
有一些视频游戏非常难,强化学习方法和视觉语言模型(VLMs)都很难解决。这些游戏通常包含语言元素、需要长时间探索的目标,或者空间推理谜题。BALROG 基准测试就包含了这些类型的游戏,并为 VLMs 提供了进展指标。AI在游戏领域的经典案例之一是 NetHack,这是一款极其复杂的网格世界游戏,游戏里有复杂的战斗、物品和地下城系统,还带有随机化,导致人类很难完成它。
VideoGameBench 跟 BALROG 那种“探索+解谜”的游戏测试稍微不一样。它的核心是:选一批真实存在的、有代表性的经典游戏(比如《Pokemon Red》、《Doom》),让大模型或 RL agent 来挑战这些游戏。
为什么这些游戏能被用来测 AI?因为它们其实已经有 RL 解法了——比如口袋红版已经多次被 RL 通关,《Doom》也有 RL 平台可用。
但有个不同点:RL 方法是从头训练模型玩游戏;而 VLM 模型并不会专门训练这些游戏,只是“顺带学”到了一点点相关知识。所以,两者获得的信息量完全不同,难度也不一样。
最近,大家开始更多关注如何用新的前沿模型和智能体方法来解决这些游戏,比如 Claude 和 Gemini 玩宝可梦(Gemini 使用了一种更有意思的智能体方式)。另一个重大的项目是 Hao AI 实验室,他们正在构建一个平台,让 VLM 智能体能够实时玩《超级马里奥》、《仓鼠迷宫》和《糖果传奇》等游戏。
VideoGameBench 和 VideoGameBench-Lite 专注于真实的视频游戏,采用一组固定且有挑战性的游戏(比如平台游戏、射击游戏、即时战略、角色扮演游戏,2D、2.5D、3D等),并使用统一的接口。这些环境设计得也很灵活,未来可以很方便地插入各种模拟器。

最后的思考:为什么我们要让 AI 玩游戏?
让 AI 玩游戏这事,其实不仅是个“炫技”展示,也很有研究意义。它能很好地测量模型的综合推理能力。
相比于复杂到离谱的数学题或奥赛题目,打游戏并不是“超人类”的任务,但现在的模型却还是过不了第一关。
而且,大部分研究都集中在纯文本的推理上,很少有人关注这种“图像 + 操作 + 策略”的多模态任务,这正是 VLM 的短板。因此,VideoGameBench 不只是个游戏挑战平台,更是一种新型的 AI 测试基准,代表着大模型在多模态理解上的真实表现力。
对此感兴趣的小伙伴可以通过 GitHub 项目地址了解更多:
https://github.com/alexzhang13/videogamebench
来源:https://www.vgbench.com/#ref-17
推荐阅读:
▶一人连肝7年!独立游戏最惨「翻车现场」:3.7万张手绘+500首配乐,结果连个差评都等不到……

为开发者提供按需使用的算力基础设施。
更多推荐


 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)