

编程新时代:Amazon CodeWhisperer 助您轻松驾驭代码世界
编程新时代:Amazon CodeWhisperer 助您轻松驾驭代码世界

文章目录
一、什么是 Amazon CodeWhisperer?
Amazon CodeWhisperer 是一款由机器学习提供支持的代码生成器,可实时提供代码建议。当在 IDE 中编写代码时,CodeWhisperer 会根据你的注释和现有代码自动生成建议。
它支持 15 种编程语言,包括 Python、Java 和 JavaScript,以及您最喜欢的集成开发环境 (IDE),包括 VS Code、IntelliJ IDEA、AWS Cloud9、AWS Lambda 控制台、JupyterLab 和 Amazon SageMaker Studio。

以下是亚马逊的 CodeWhisperer 工具如何根据文本输入生成代码:

在PyCharm和VSCode中,Amazon CodeWhisperer都展现出了良好的使用流畅性。无论是插入代码,还是切换不同的功能,响应速度都非常快,没有出现任何卡顿或延迟,为用户提供了愉快的编程体验。
二、个人无限免费使用
值得一提的是,CodeWhisperer为个人开发者提供了免费的个人套餐。只需使用电子邮箱和AWS构建者ID进行简单注册和登录,个人开发者便可以在几分钟内开始享受CodeWhisperer带来的便利。个人套餐不仅提供了代码建议功能,还包括了引用跟踪和安全扫描等实用功能,充分满足了个人开发者在编程过程中的多方面需求。

接下来,我们将详细介绍如何在不同的编程环境中配置和使用CodeWhisperer。
三、安装配置
在PyCharm和VSCode中安装Amazon CodeWhisperer的过程非常简单直观,用户只需在插件市场搜索并安装“AWS Toolkit”即可,无需复杂的配置。这使得用户能够快速上手,无需花费过多时间在安装和配置上。
3.1 手把手教你在pycharm配置
在PyCharm和VSCode中安装Amazon CodeWhisperer的过程非常简单直观,用户只需在插件市场搜索并安装“AWS Toolkit”即可,无需复杂的配置。这使得用户能够快速上手,无需花费过多时间在安装和配置上。
让我们来看一下Amazon CodeWhisperer。我将在PyCharm中演示如何使用它(除此之外,它还支持其他编辑器,如VS等)。首先,需要下载插件:AWS Toolkit。进入设置:
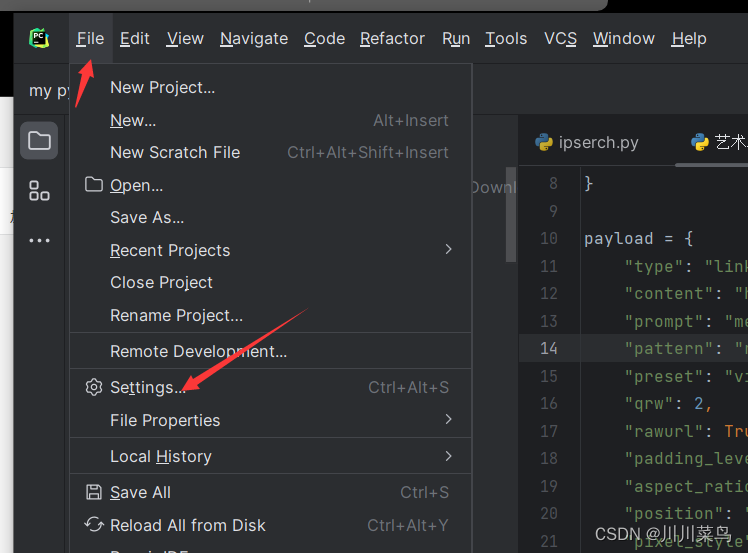
进入设置后,我们可以看到插件市场的界面是非常直观的,搜索“AWS Toolkit”后,点击“install"进行安装。

选择”apply",再点击“OK":
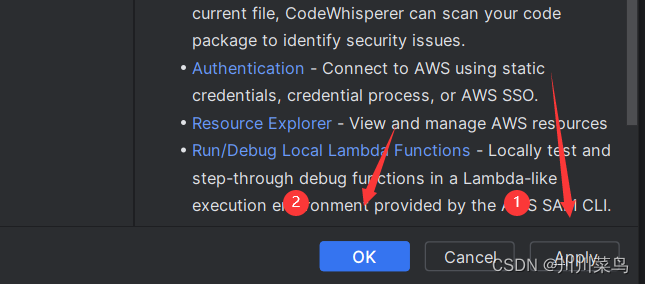
再点击重启即可:
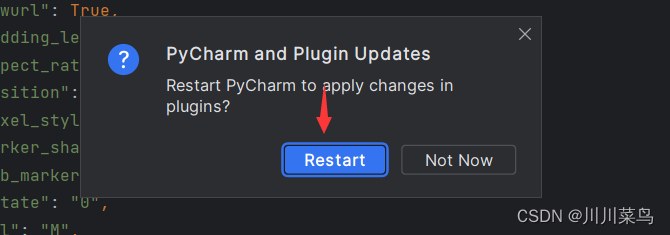
安装并重启后,我们可以在AWS Toolkit视图(菜单View/Tool Windows/AWS Toolkit)中看到CodeWhisperer的选项,这表明我们已经成功安装并可以开始使用了。

接着,点击"Developer Tools"tab⻚⾯,选择“CodeWhisperer/Start",如下图所示:

弹出界面,点击”open and Copy Code“

粘贴并提交:

接下来需要登陆自己的账户:

输入密码:

此时会弹出界面”Allow AWS Toolkit for JetBrains to access your data?“,如下所示,点击”Allow":

显示“AWS Toolkit for JetBrains can now access your data.You can close this window and start using AWS Toolkit for JetBrains.”,代表可以正常连接了,配置成功!

返回pycharm可以看到,已经开启:

3.2 同理在VSCODE安装
在VSCode中,我们同样可以在插件市场中轻松找到并安装“AWS Toolkit”。安装流程与在PyCharm中类似,非常简单直观。

选择第二个:

继续:

点击允许:

配置成功:

安装成功后,VSCode界面也显示了CodeWhisperer的相关选项,这意味着我们可以开始在VSCode中使用CodeWhisperer了。

三、Pycharm上测试
在PyCharm中使用Amazon CodeWhisperer也表现出了很好的操作便捷性。用户只需根据自己的需求编写注释,CodeWhisperer就会自动弹出代码建议,用户可以轻松选择并插入代码。这一流程简单明了,即便是编程新手也能够快速上手。
3.1 根据注释写代码
在PyCharm中,我们可以轻松地根据注释生成代码。例如,我写了个注释“抓取亚马逊商城关于iphone15价格", Amazon CodeWhisperer会自动弹出建议代码的界面,我们可以选择合适的代码进行插入。

它们分别代表“插入代码”,“上一个选项”,“下一个选项”。因为它会自动为我们提供可参考的代码,选择一个合适的代码点击插入即可。
每次插入代码后,按一下键盘空格,便可以继续插入代码,根据提示不断插入代码即可。
这个功能非常实用,尤其是在完成算法题时,通过不断“空格”和”Insert Code“,我们可以轻松几秒钟完成代码。
、
下面我们来完成一个算法作业:
# 输出:按照从小到大排序后的列表。
#
# 示例:
# 输入:[5, 3, 8, 2, 1]
# 输出:[1, 2, 3, 5, 8]
通过不断“空格”和”lnsert Code“,轻松几秒钟完成代码如下:
def ipserch(arr):
for i in range(len(arr)): # 冒检
for j in range(i, len(arr)):
if arr[i] > arr[j]:
arr[i], arr[j] = arr[j], arr[i] # 位置修�]
return arr
if __name__ == "__main__":
arr = [5, 3, 8, 2, 1]
print(ipserch(arr))
运行结果完全正确,如图所示:

来完成一个作业习题:一个整数,它加上100后是一个完全平方数,再加上168又是一个完全平方数,请问该数是多少?请用python实现。如下所示:

直接给出标准答案,简直太棒了!
3.2 检查修复代码错误
在使用Amazon CodeWhisperer时,我也对其在代码安全性方面的表现进行了测试和评估。CodeWhisperer不仅能够生成高质量的代码,还具备识别的能力,下面演示为一个简单的识别修复代码。
这是我开始的代码,刻意在这留了一个错误:

执行CodeWhisperer自动修复:

3.3 构建一个简单爬虫
在构建网络爬虫时,我们只需在注释中写明需求,Amazon CodeWhisperer就能为我们生成相应的代码,极大地提高了开发效率。
# 写一个爬虫,模拟打开百度,输入“川川菜鸟”并回车
# 然后点第一个页面进去查看
# 用selenium框架
得到如下:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
time.sleep(3)
driver.find_element_by_id("kw").send_keys("川川菜鸟") # 输入内容
driver.find_element_by_id("su").click() # 点击搜索
接下来继续把需求写在注释中,不断写清楚注释即可,得到对应代码:
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
time.sleep(3)
driver.find_element(By.ID,'kw').send_keys("川川菜鸟") # 输入内容
driver.find_element(By.ID,'su').click() # 点击
# 鼠标滑动180度
js = 'document.documentElement.scrollTop=180'
driver.execute_script(js)
time.sleep(3)
四、 VSCODE上测试
与在PyCharm中类似,VSCODE上的Amazon CodeWhisperer同样操作简便。通过快捷键“Alt+c"运行CodeWhisperer后,用户可以轻松地根据注释生成代码,检查代码错误,并尝试新的编程语言。这种便捷的操作方式大大降低了用户的上手难度,提高了编程效率。
4.1 个性化体验
在使用过程中,Amazon CodeWhisperer展现出了很好的个性化体验。它能够记忆我的编程风格,并根据我的习惯提供合适的代码建议,这让我感到非常舒适,也极大地提高了我的编程效率。
4.2 系统兼容性
我在Windows系统上分别测试了Amazon CodeWhisperer在PyCharm和VSCode中的表现,发现其在这两种IDE中都能够稳定运行,与IDE完美整合,表现出了良好的系统兼容性。
4.3 根据注释写代码
如下所示,首先让它根据我的要求写一个函数,然后写一个示例。
# 写一个求两数和
def add(a,b):
return a+b
# 给个示例
print(add(1,2))
4.4 尝试一门新的语言
通过Amazon CodeWhisperer的帮助,我尝试学习了C++,并成功完成了一些基础练习。这个工具为我提供了丰富的示例代码和实时建议,使我能够快速入门新的编程语言。

输入3个数,求最大值:

4.5 代码生成质量
在使用Amazon CodeWhisperer的过程中,我特别注意到了它生成的代码质量。无论是在完成算法题目还是构建网络爬虫应用时,CodeWhisperer生成的代码都表现出了很高的标准。
符合编程规范:
生成的代码结构清晰,命名规范,符合Python和C++的编程规范,这使得代码易于理解,也方便了后续的代码维护。例如,在生成排序算法和网络爬虫代码时,函数命名清晰,逻辑结构合理,代码间的缩进和空行也都符合规范,显示出了CodeWhisperer对编程规范的遵循。
可读性:
CodeWhisperer生成的代码具有很高的可读性。代码逻辑清晰,注释充分,即便是对于编程新手,也能够快速理解代码的功能和运作机制。这一点在我尝试学习新的编程语言C++时表现得尤为明显,CodeWhisperer的代码建议帮助我快速理解了C++的语法和结构。
可维护性:
生成的代码模块化程度高,函数划分合理,这使得代码具有很好的可维护性。即使在后期需要对代码进行修改和扩展,也能够轻松进行,大大提高了开发效率。
五、实战网络爬虫:抓取csdn热榜数据
提供注释如下:
# 使用selenium爬取热榜
# 热榜地址:https://blog.csdn.net/rank/list
# 获取标题、浏览量、评论数量、收藏数量
初次执行,自动插入相关模块,不用手动敲了,省时间
from selenium import webdriver
import time
import csv
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
继续执行CodeWhisperer,写出一个请求函数用来打开网页:
def get_data(url):
driver = webdriver.Chrome()
driver.get(url)
time.sleep(5)
我们目标是获取到对应数据,因此添加注释,执行CodeWhisperer
# 打开热榜地址
插入代码如下:

打开后又做什么呢?获取标题标题、浏览量、评论数量、收藏数量,因此分别添加注释如下,执行CodeWhisperer
#添加等待10秒
如下所示:

继续不断添加注释:
# 等待直到页面加载完成
# 获取所有的文章元素
# 创建或打开CSV文件,准备写入数据:浏览量、评论数量、收藏数量
执行CodeWhisperer,如下所示:

其中获取所有元素需要人工调整,定位查看,复制出来即可:

接下来需要遍历获取所有内容,添加注释:
# 遍历所有文章元素,提取所需数据:浏览量、评论数量、收藏数量
执行CodeWhisperer,插入代码如下:

同理,定位元素部分需要手动调整,这里可以看一个标题定位例子,其它同理:

继续执行CodeWhisperer完成一些剩余的代码,此时完整代码如下:
def get_data(url):
driver = webdriver.Chrome()
driver.get(url)
# 添加等待
wait = WebDriverWait(driver, 10)
try:
# 等待直到页面加载完成
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div.hostitem.floor")))
# 获取所有的文章元素
product_elements = driver.find_elements(By.CSS_SELECTOR, "div.hostitem.floor")
# 创建或打开CSV文件,准备写入数据:浏览量、评论数量、收藏数量
with open('output.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["Title", "View", "Comment", "Collect"]) # 写入表头
# 遍历所有文章元素,提取所需数据:浏览量、评论数量、收藏数量
for index, product in enumerate(product_elements):
title = product.find_element(By.CSS_SELECTOR, "div.hosetitem-title > a").text
view = product.find_element(By.CSS_SELECTOR, "div.hosetitem-dec > span:nth-child(1)").text
comment = product.find_element(By.CSS_SELECTOR, "div.hosetitem-dec > span:nth-child(3)").text
collect = product.find_element(By.CSS_SELECTOR, "div.hosetitem-dec > span:nth-child(5)").text
# 打印到控制台
print(f"Product {index + 1}:")
print(f"Title: {title}")
print(f"View: {view}")
print(f"Comment: {comment}")
print(f"Collect: {collect}")
# 写入到CSV文件
writer.writerow([title, view, comment, collect])
except Exception as e:
print(f"An error occurred: {e}")
finally:
# 确保关闭WebDriver,释放资源
driver.quit()
输出结果如下,只抓取到了25个数据:

我发现网页数据抓取我只获取到了25个,如果想要获取后面内容,需要往下翻才会加载25到50的数据,同理继续翻才能加载出25到75数据。为了加载更多的数据,需要模拟滚动页面才能完成。因此思路是:先滚动加载出全部数据,再进行抓取。
添加注释到获取所有的文章元素上面:
# 滚动页面以加载更多数据
如下:

此时我们可以看到已经完成全部数据抓取:

保存在csv文件如下:

通过CodeWhisperer的辅助,写代码时间真的省了好多,有更多时间摸鱼了~
完整代码如下:
# 书籍介绍·:https://chuanchuan.blog.csdn.net/article/details/133050678
# 使用selenium爬取热榜
# 热榜地址:https://blog.csdn.net/rank/list
# 获取标题、浏览量、评论数量、收藏数量
from selenium import webdriver
import time
import csv
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def get_data(url):
driver = webdriver.Chrome()
driver.get(url)
# 添加等待
wait = WebDriverWait(driver, 10)
try:
# 等待直到页面加载完成
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div.hostitem.floor")))
# 滚动页面以加载更多数据
for _ in range(4):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)
# 获取所有的文章元素
product_elements = driver.find_elements(By.CSS_SELECTOR, "div.hostitem.floor")
# 创建或打开CSV文件,准备写入数据:浏览量、评论数量、收藏数量
with open('output.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["Title", "View", "Comment", "Collect"]) # 写入表头
# 遍历所有文章元素,提取所需数据:浏览量、评论数量、收藏数量
for index, product in enumerate(product_elements):
title = product.find_element(By.CSS_SELECTOR, "div.hosetitem-title > a").text
view = product.find_element(By.CSS_SELECTOR, "div.hosetitem-dec > span:nth-child(1)").text
comment = product.find_element(By.CSS_SELECTOR, "div.hosetitem-dec > span:nth-child(3)").text
collect = product.find_element(By.CSS_SELECTOR, "div.hosetitem-dec > span:nth-child(5)").text
# 打印到控制台
print(f"排名:{index + 1}")
print(f"标题: {title}")
print(f"浏览量: {view}")
print(f"评论量: {comment}")
print(f"收藏量: {collect}")
# 写入到CSV文件
writer.writerow([title, view, comment, collect])
except Exception as e:
print(f"An error occurred: {e}")
finally:
# 确保关闭WebDriver,释放资源
driver.quit()
url='https://blog.csdn.net/rank/list'
get_data(url)
六、官方文档
对于深入了解和掌握CodeWhisperer的用户来说,官方文档是一份极佳的学习资料。文档中详尽地列出了各项功能说明、操作截图以及实际演示,有助于用户全面而深入地理解和运用CodeWhisperer。更多的使用方法和相关操作,可参考官方文档:CodeWhisperer ,这里有详细的使用教程,有截图和演示,能帮助开发者更好的使用起来:

该网站提供了丰富的使用教程、实际截图和演示,助力开发者更加便捷高效地使用该工具。

为开发者提供按需使用的算力基础设施。
更多推荐



 33
33 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)