
stable diffusion 百宝书
去下方网站获取git的win安装包,之后不断点击下一步就可以了:安装完之后,运行唤出控制台,执行如下命令检验是否安装完成0.1.2 python 环境搭建去下方网站获取python的win安装包,之后不断点击下一步就可以了。在最后一步,一定要选择环境变量。安装完之后,运行唤出控制台,执行如下命令检验是否安装完成0.1.2.1 配置pip国内镜像源运行唤出控制台,输入如下命令0.1.3 stable
0. 环境搭建
0.1 Windows
0.1.1 git环境安装
去下方网站获取git的win安装包,之后不断点击下一步就可以了:
https://git-scm.com/
安装完之后,运行Win+R唤出控制台,执行如下命令检验是否安装完成
git --version
0.1.2 python 环境搭建
去下方网站获取python的win安装包,之后不断点击下一步就可以了。在最后一步,一定要选择 Add python.ext to PATH 环境变量。
https://www.python.org/
安装完之后,运行Win+R唤出控制台,执行如下命令检验是否安装完成
python --version
0.1.2.1 配置pip国内镜像源
运行Win+R唤出控制台,输入如下命令
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
0.1.3 stable diffusion环境搭建
- 去想要安装的盘符上新建个文件夹用于存放stable diffusion的相关信息
- 下载stable diffusion的开源仓库
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
- 如果没问题的话,在当前目录会存在一个
webui-user.bat这个批处理文件,双击运行 - 在批处理的控制台会出现如下信息
Running at local url:http://127.0.0.1:7860类似的信息,复制这个网址,用浏览器打开
0.1.3.1 远程访问Stable diffusion
远程访问主要有两种方式:
- 内网穿透:依赖内网穿透软件(比如花生壳),这样可以在公网环境访问你的远端stable diffusion,随时出图。但是这依赖我们在批处理文件之中设置如下的启动参数:
set COMMANDLINE_ARGS= --listen
- 批处理启动参数:如果你的远端环境可以访问外网,可以在批处理文件中增加如下述的启动命令:
set COMMANDLINE_ARGS= --share
注:不能同时设置listen和share参数,因为listen参数的优先级会更高
0.1.3.2 模型 Lora下载
- 访问相关模型网站,我们这里拿著名的C站(https://civitai.com/)举例:
注:同学也可以访问国内模型网站libai(https://www.liblib.ai/)

- 点击自己喜欢的模型,选择下载

- 将下载后的文件放到stable diffusion指定的目录下
盘符:\目录\stable-diffusion-webui\models\Stable-diffusion
注: Lora下载放到这个目录
盘符:\目录\stable-diffusion-webui\models\Lora
- 点击stable diffusion的刷新按钮,就可以刷新了

1. SD 基础
Stable Diffusion是2022年发布的深度学习文本到图像生成模型,它是一种潜在扩散模型,它由创业公司Stability AI与多个学术研究者和非营利组织合作开发。目前的SD的源代码和模型都已经开源,在Github上由AUTOMATIC1111维护了一个完整的项目,正在由全世界的开发者共同维护。由于完整版对网络有一些众所周知的需求,国内有多位开发者维护着一些不同版本的封装包。
1.1 文生图基本原理
由于本人不是相关研究方向的学者,这里只是简述一下基本原来,如有错误,欢迎各位大佬批评指正。
当用户输出一段提示词之后,比如说宇航员骑狗,其首先会被解析为两个特征向量宇航员、狗。然后去对应的数据库之中找到对应的图像,之后将这一部分特征向量信息传递到图像编码器之中。图像编码器会从潜在空间之中选取一张初始噪声图片。然后U-net卷积神经网络会根据特征向量预测出不需要的噪声,与原噪声相减得到一张新的噪声图,如此不断往复,之后会得到一张满足需求的特征图像,最终由图像解码器将其解析为呈现给用户的最终图像。
潜在空间:反映的是原始数据经过“中介空间”后的特征

1.2 Stable Diffusion实战
说完了基本原理,我们接下来就进入Stable Diffusion的实战环节。
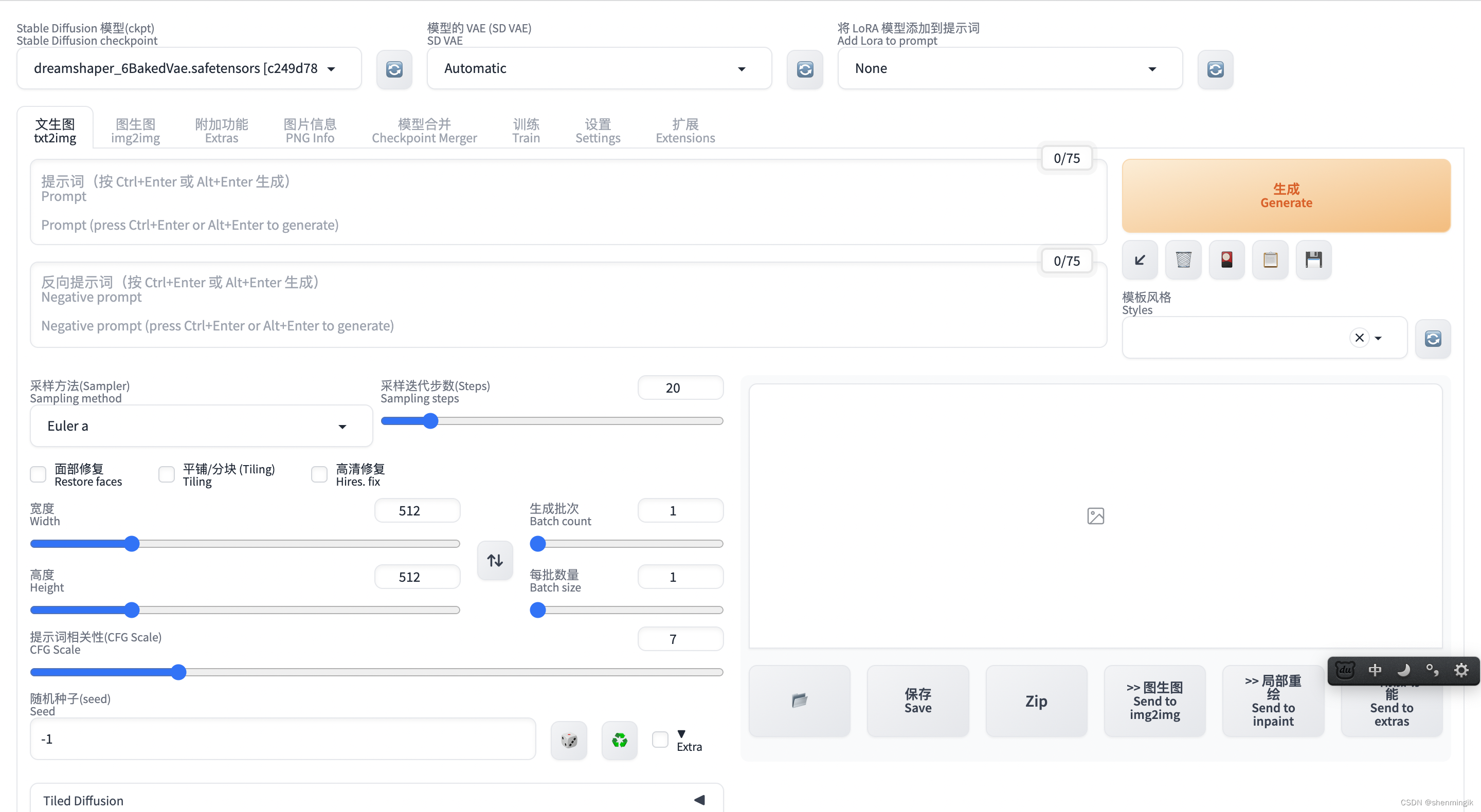
下图是Stable Diffusion的Web ui展示:

1.2.1 基本参数说明
上图之中存在着很多参数,我这里按照对用户的重要性来逐一说明:
| 参数 | 含义 |
|---|---|
| 采样方法 | 采用方法其实就是刚刚讲原理时提到的降噪方法,SD提供了很多方法,这里根据用户需求简单分类了一下 如果只是想得到一些较为简单的结果:选用欧拉(Eular)或者Heun 对于侧重于速度、融合、新颖且质量不错的结果: * DPM++ 2M Karras, Step Range:20-30 * UniPc, Step Range: 20-30 期望得到高质量的图像,且不关心图像是否收敛: * DPM ++ SDE Karras, Step Range:8-12 * DDIM, Step Range:10-15 |
| 采样迭代步数 | 控制降噪的轮次,选择50就是降噪50轮之后将图像经过解码器返回给用户 |
| 提示词相关性 | 对于人物类的提示词,一般将提示词相关性控制在 7-15 之间; 而对于建筑等大场景类的提示词,一般控制在 3-7 左右 |
| 模型 | 用素材+SD底模(如SD1.5/SD1.4/SD2.1),深度学习之后炼制出的大模型,可以直接用来生图。大模型决定了最终出图的大方向 。 大模型被称为checkpoint,一般3-7GB |
| VAE | 类似类似美颜工具之中的滤镜,是对大模型的补充,稳定画面的色彩范围 |
| LoRA模型 | 大模型的低秩适应,可以理解为模型插件。其是在基于某个大模型的基础上,深度学习之后炼制出的小模型。需要搭配大模型使用,可以在中小范围内影响出图的风格,或是增加大模型所没有的东西。 |
| ControlNet | 能够基于现有图片得到诸如线条或景深的信息,去知道SD扩散模型如何去生成图片 |
1.2.1.1 模型
• 模型类目
模型大致可以分为三个类别:
- 二次元类:插画、漫画风
- 真实系:真实风格
- 2.5D风格:介于二者之间的
不同类模型,以及不同模型之间的出图效果都十分不一样,可以看一下在同一参数场景下不同。模型的出图效果对比:
• 推荐查找关键词
| 二次元模型 | 真实系模型 | 2.5D模型 | |
|---|---|---|---|
| 推荐标签与风格关键词 | illustration,painting,skectch,drawing,comic,anime,cartoon | photography,photo,realistic,photorealistic,Raw photo | 3D,render,chibi,digital art,concept art,{realistic} |
• 模型推荐

1.2.1.2 采样方法
采样方法总结:
- 如果只是想得到一些较为简单的结果:选用欧拉(Eular)或者Heun
- 对于侧重于速度、融合、新颖且质量不错的结果:
DPM++ 2M Karras, Step Range:20-30UniPc, Step Range: 20-30- 期望得到高质量的图像,且不关心图像是否收敛:
DPM ++ SDE Karras, Step Range:8-12DDIM, Step Range:10-15
- Euler : 基于Karras论文,在K-diffusion实现,20-30steps就能生成效果不错的图片,采样器设置页面中的 sigma noise,sigma tmin和sigma churn这三个属性会影响到它
- Euler a: 使用了祖先采样(Ancestral sampling)的Euler方法,受采样器设置中的eta参数影响
- LMS:线性多步调度器(Linear multistep scheduler)源于K-diffusion的项目实现
- heun:基于Karras论文,在K-diffusion实现,受采样器设置页面中的 sigma参数影响
- DPM2:这个是Katherine Crowson在K-diffusion项目中自创的,灵感来源Karras论文中的DPM-Solver-2和算法2,受采样器设置页面中的 sigma参数影响;DPM2 a使用了祖先采样(Ancestral sampling)的DPM2方法,受采样器设置中的ETA参数影响
- DPM++ 2S a:基于Cheng Lu等人的论文(改进后,后面又发表了一篇),在K-diffusion实现的2阶单步并使用了祖先采样(Ancestral sampling)的方法,受采样器设置中的eta参数影响;Cheng Lu的github中也提供已经实现的代码,并且可以自定义,1、2、3阶,和单步多步的选择,webui使用的是K-diffusion中已经固定好的版本。对细节感兴趣的小伙伴可以参考Cheng Lu的github和原论文。
- DPM++ 2M:基于Cheng Lu等人的论文(改进后的版本),在K-diffusion实现的2阶多步采样方法,在Hagging face中Diffusers中被称作已知最强调度器,在速度和质量的平衡最好。这个代表M的多步比上面的S单步在采样时会参考更多步,而非当前步,所以能提供更好的质量。但也更复杂。
- DPM++ SDE:基于Cheng Lu等人的论文的,DPM++的SDE版本,即随机微分方程(stochastic differential equations),而DPM++原本是ODE的求解器即常微分方程(ordinary differential equations),在K-diffusion实现的版本,代码中调用了祖先采样(Ancestral sampling)方法,所以受采样器设置中的ETA参数影响
- DPM fast: 基于Cheng Lu等人的论文,在K-diffusion实现的固定步长采样方法,用于steps小于20的情况,受采样器设置中的ETA参数影响
- DPM adaptive: 基于Cheng Lu等人的论文,在K-diffusion实现的自适应步长采样方法,DPM-Solver-12 和 23,受采样器设置中的ETA参数影响
- Karras后缀:LMS Karras 基于Karras论文,运用了相关Karras的noise schedule的方法,可以算作是LMS使用Karras noise schedule的版本;
同样的不同的采样方法会得到不同效果的图片:

1.2.1.3 采样迭代步数
输出画面需要的步数,每一次采样步数都是在上一次的迭代步骤基础上绘制生成一个新的图片,一般来说采样迭代步数保持在 18-30 左右即可,低的采样步数会导致画面计算不完整,高的采样步数仅在细节处进行优化,对比输出速度得不偿失。

1.2.1.4 提示词相关性
Stable Diffusion 中的提示词相关性指的是输入提示词对生成图像的影响程度。当我们提高提示词相关性时,生成的图像将更符合提示信息的样子;相反,如果提示词相关性较低,对应的权重也较小,则生成的图像会更加随机。
因此,通过调整提示词相关性,可以引导模型生成更符合预期的样本,从而提高生成的样本质量。
- 在具体应用中,对于人物类的提示词,一般将提示词相关性控制在 7-15 之间;
- 而对于建筑等大场景类的提示词,一般控制在 3-7 左右。这样可以在一定程度上突出随机性,同时又不会影响生成图像的可视化效果。
因此,提示词相关性可以帮助我们通过引导模型生成更符合预期的样本,从而提高生成的样本质量。

1.2.1.5 随机种子
随机种子是一个可以锁定生成图像的初始状态的值。当使用相同的随机种子和其他参数,我们可以生成完全相同的图像。设置随机种子可以增加模型的可比性和可重复性,同时也可以用于调试和优化模型,以观察不同参数对图像的影响。
在 Stable Diffusion 中,常用的随机种子有-1 和其他数值。当输入-1 或点击旁边的骰子按钮时,生成的图像是完全随机的,没有任何规律可言。而当输入其他随机数值时,就相当于锁定了随机种子对画面的影响,这样每次生成的图像只会有微小的变化。因此,使用随机种子可以控制生成图像的变化程度,从而更好地探索模型的性能和参数的影响。

1.2.2 SD 实战
1.2.2.1 基础功能
了解完Stable Dissusion最基础的参数之后,我们可以尝试去绘制一幅宇航员骑狗的图片。
在这里我们选择基本的绘图参数:
- 模型:3H混合超细节机甲
- 采样方法:DPM++ 2S a Karras
- 采样迭代步数: 30
- 尺寸: 512*512
- 提示词相关性: 7
- 随机种子:2060336848
- 提示词:
- 内容提示词:
Astronauts riding dogs - 画质提示词:
- 正向:
Posters, wallpapers,best quality,highly detailed,masterpiece,ultra-detailed,illustratio - 反向:
lowres,bad hands,text,error,cropped,worst quality,low quality,normal quality,jpeg artifacts,watermark,username,blurry,blurryd
- 正向:
- 场景提示词:
simple background
- 内容提示词:

结果如下:

1.2.2.2 高清修复
我们可以看到上面的图片尺寸比较小,这是因为显卡显存(笔者电脑只有8G)的限制导致。如果我们想在小显存上面获得比较清晰的图像,我们可以使用Stable Diffusion的高清修复功能。
高清修复参数:
放大倍数:是指放大到原图的多少倍,也可以按照参数后面手动设置新图像的宽和高
重绘幅度:是和原图的差异度,一般推荐0.5,安全放大区间0.3-0.5,具有自由度区间0.5-0.7
高清采样次数:和采样迭代数一样,不用选择,保持默认0的迭代次数
放大算法:网上推荐无脑选择R-ESRGAN 4x+ 的,二次元的选择R-ESRGAN4x+ Anime6B,效果相较于其他算法是好一点的。
GFPGAN 可见度:人脸修复功能,能够让这些老照片恢复原有的光泽,使用了GAN算法对照片进行修复,效果比其他同类模型都有更好的表现。
CodeFormer 可见度:马赛克修复功能,这是一种基于 Transformer 的预测网络,能够对低质量人脸的全局组成和上下文进行建模以进行编码预测,即使在输入信息严重缺失的情况下也能复原出与目标人脸非常接近的自然人脸图像。
高清修复主要有两种办法:
- 附加功能:分两步,第一步生成低分辨率的图画,第二步使用它指定的高清算法,生成一个高分辨率的版本,在不改变构图的情况下丰富细节。缺陷就是生成图片的大小受限于显存的大小。

- SD放大:根据指定的放大倍数,将图生图的图像拆解成若干小块按照固定逻辑重绘,再合并成一张大图,可以实现在低显存的条件下生成大尺寸的图片。这种方法除了指定SD脚本所需参数之外,还需要指定相关的提示词。
注:由于原理是拼合,所以为了拼合更加合理,所以需要设置图像重叠像素。设置完之后,图像尺寸应该是原尺寸+重合像素的大小


1.2.2.3 局部重绘
局部重绘就是将图片中我们不满意的地方进行重新绘制,直到达到用户满意的程度。我们刚刚骑的是狗,现在来骑马试试。
局部重绘参数说明:
蒙版:蒙住关键区域的板子,重绘图中黑色区域就是蒙版
蒙版模式:默认选择“重绘蒙版内容”,如果是“重绘非蒙版内容”就是重绘黑色区域以外的内容
重绘区域:就是你要求AI重绘的时候你所提供的信息,默认“原图”,如果选择“仅蒙版”,那么AI得不到全图信息,重绘后的部分会和其他的地方有割裂感。如果你选的是仅蒙版模式,要对于右侧的仅蒙版模式的边缘预留像素进行调整,默认32。这个预留像素的意思就是缓冲带,使得重绘拼图的时候看上去更加自然。
蒙版模糊:类似PS羽化效果,使得拼接更加丝滑
蒙版蒙住的内容:随便选,看缘分
点击【图生图】–> 【局部重绘】

我们维持提示词不变,在提示词后面添加需要改动的提示词,在参数重绘幅度开到一个比较高的数值,比如0.75,当把鼠标移动到图片区域会出现一个画笔笔尖,在图片中你想要更改的地方涂上黑色区域,画错了还有撤销和橡皮擦功能在右上角可以使用


1.2.2.4 ControlNet
Control Net是一款可以对Stable Diffusion扩散模型进行精确控制的插件。在SD安装之后我们可以在Web ui之中找到如下的ControlNet选项:

参数说明:
控制单元:一个ControlNet单元描述了一种对扩散模型的提示,如果想要有多个提示可以在【设置】–> 【ControlNet】–>【Multi ControlNet】选择单元数量。
效果预览:在上方存在两个出图的地方,右边就是预览效果图片的地方
ControlWeight:控制权重,表示ControlNet的提示信息的权重占比
ControlType:控制类型,会识别用户传入的控制信息,将其描绘为简单的表述形式。主要包含以下几种:
- 姿态控制(OpenPose):会识别用户传入人物的姿态信息,是用来解决AI不会画手的大杀器。
- 精确控制(Canny):会识别用户传入的所有信息,将其和Prompt结合生成新的图像。
- 画面分割(Seg):识别用户传入的元素布局,将其进行不同的归类,用以控制画面大体细节不变。
- 深度控制(Depth):即深度图,用以传入空间信息给扩散模型
下面我们会通过实操来掩饰这几种控制类型的效果。
参数信息如下:
- 模型:3H混合超细节机甲
- 采样方法:DPM++ 2S a Karras
- 采样迭代步数: 30
- 尺寸: 512*512
- 提示词相关性: 7
- 随机种子:2060336848
- 提示词:
- 内容提示词:
a humanoid robot, full body, facing viewer, - 画质提示词:
- 正向:
Posters, wallpapers,best quality,highly detailed,masterpiece,ultra-detailed,illustratio - 反向:
lowres,bad hands,text,error,cropped,worst quality,low quality,normal quality,jpeg artifacts,watermark,username,blurry,blurryd
- 正向:
- 场景提示词:
simple background
- 内容提示词:
1.2.2.4.1 姿势控制
当我们上传图片之后,选择OpenPose姿态控制,之后点击爆炸。右边就会生成我们上传图片的骨骼图。


1.2.2.4.2 精确控制
当我们上传图片之后,选择Canny姿态控制,之后点击爆炸。右边就会生成我们上传图片的线稿图。


1.2.2.4.3 画面分割
当我们上传图片之后,选择Seg姿态控制,之后点击爆炸。右边就会生成我们上传图片的画面分割。


1.2.2.4.4 深度图
由于刚刚的图片没有空间感,所以我们需要换一下内容提示词:
- 内容提示词:
Palace, Architecture,no human,


2. SD 商业应用场景
2.1 吉祥物
下面是淘宝天猫的一个例子:
模型:RevAnimated
Lora:粿条Tmall model 3D卡通天猫场景

2.2 商品展示
以化妆品来举例:
模型:chilloutmix
Lora:自然美妆场景

2.3 LOGO
模型:3H机甲
Lora:None
ControlNet:Depth

注:森马已经用上了
2.4 商品模型
通过将产品的图片喂给模型,生成对应商品模型。之后便可以对这个商品进行快速出图。

附: 不同显卡出图效率

3. 扩展插件推荐
可以在stable diffusion中的【扩展】–>【从网址安装】安装不同的扩展

3.1 中文语言包
让SD支持中文:
- github: https://github.com/journey-ad/sd-webui-bilingual-localization
3.2 图库浏览器
方便浏览作品,进行多种查询和管理
- github:https://github.com/AlUlkesh/stable-diffusion-webui-images-browser
注:刚开始不显示图片信息,点击”首页“标签,就会加载好以前的图片
3.3 Tag Autocompletion:实现提示词的补全、翻译
Tag Autocompletion:实现提示词的补全、翻译
有像只能输入法,可以帮你智能补全提示词,并为你推荐更适合AI明白的提示词
它还包含热门IP,比较方便
输入尖括号<>,输入e、l、h就可以自动加载embeddings,lora,hypeenetwork模型
链接:http://www.123114514.xyz/WebUI/Tag
下载那个zip,将解压后的安装包放到extension文件夹里面

3.4 SD upscale
可以看成SD脚本放大功能的高级版,提供更多的绘制选项和更好的放大效果
在安装包的这个包里面下载,同样放置在extension文件夹

重新打开SD,在图生图选项中可以找到。

参考文献
- Stable Diffusion-采样器篇 --> 1.2.1 采样方法
- stable diffusion webui如何工作以及采样方法的对比 --> 1.2.1 采样方法
- 万字保姆级教程!Stable Diffusion完整入门指南 --> 1.2 参数说明

为开发者提供按需使用的算力基础设施。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)