
经典语义分割(二)医学图像分割模型UNet
经典语义分割(二)医学图像分割模型UNet
经典语义分割(二)医学图像分割模型UNet
-
我们之前介绍了全卷积神经网络( FCN) ,FCN是基于深度学习的语义分割算法的开山之作。
-
今天我们介绍另一个语义分割的经典模型—UNet,它兼具轻量化与高性能,通常作为语义分割任务的基线测试模型,至今仍是如此。
-
UNet从本质上来说也属于一种全卷积神经网络模型,它的取名来源于其架构形状:模型整体呈现
U形。- 它原本是为了解决
医疗影像语义分割问题的。在2015年的ISBI细胞跟踪挑战赛中,Ronnebreger等人利用UNet网络以较大优势赢得比赛。- 由于隐私问题、注释过程的复杂性、专家技能要求以及使用生物医学成像系统拍摄图像的高价格,在生物医学任务中,收集大量的数据很困难。
- 而UNet能够在小样本数据集上训练并取得优秀成绩,因此各种基于其改进的网络模型广泛运用于医学图像分割任务中。特别是在肺结节、视网膜血管、皮肤病以及颅内肿瘤四大医学分割领域,出现了大量基于U-Net 改进的模型。
- 下面几点或许能够解释为何UNet在医疗影像上表现突出:
- UNet的U形网络结构密集融合了浅层特征与深层特征;
- 医疗影像数据量与UNet模型体量上相匹配,有效避免了过拟合;
- 医疗影像结构简单且固定,具有较低语义信息。
- 不过,之后几年的发展,也证实了它是语义分割任务中的全能选手。
- 它原本是为了解决
-
论文地址:U-Net: Convolutional Networks for Biomedical Image Segmentation
-
图像分割综述可参考:图像分割-综述篇
1 UNet网络
1.1 UNet网络简述
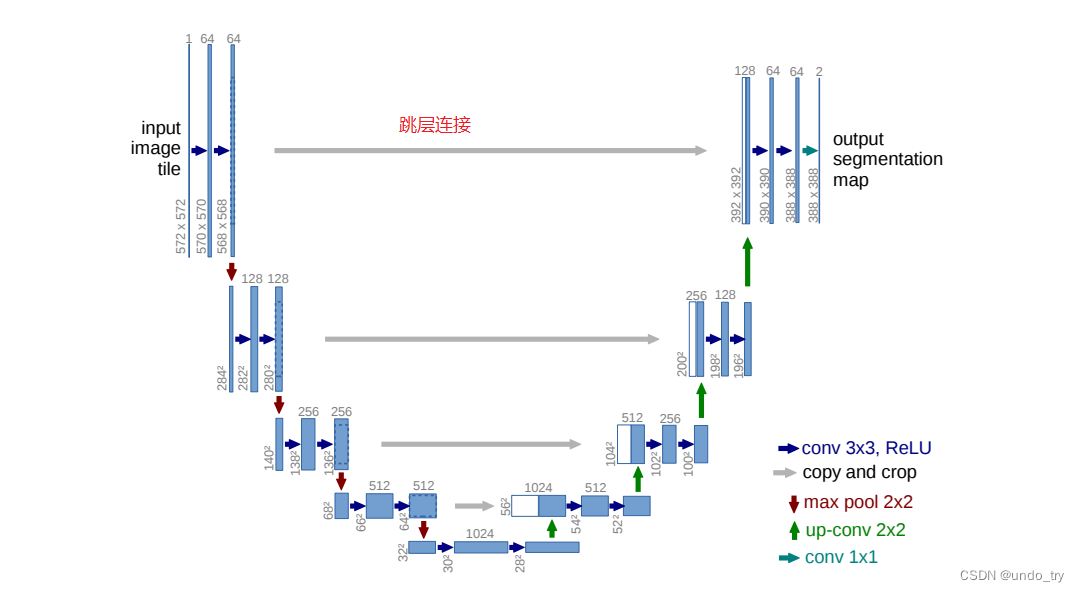
UNet网络结构如下图所示,最主要的两个特点是:U型网络结构和Skip Connection跳层连接。
-
Unet通过跳接的U形网络结构结合了浅层特征与深层特征,用于最后的语义分割图生成。
- 与FCN不同的是,UNet以拼接方式来结合浅层特征与深层特征;
- 而FCN则是以相加方式来结合浅层特征与深层特征;
-
U形网络架构能够更充分地融合浅层特征和深层特征,这也是UNet性能优于FCN的主要原因。
-
浅层特征图更倾向于表达例如点、线、边缘轮廓等基本特征单元;蕴含的空间信息更多。
-
深层特征图更倾向于表达图像的语义信息;蕴含的空间信息更少,语义特征更多。
-

1.2 网络架构详解
UNet的主干分为对称的左右两部分:
-
左边为特征提取网络(编码器,encoder),原始输入图像通过卷积-最大池化进行四次下采样,获得四层级的特征图;
-
右边为特征融合网络(解码器,decoder),各层级特征图与经过反卷积获得的特征图通过跳接方式进行特征融合;
-
最后一层通过与标签计算损失进行语义图预测。
1.2.1 DoubleConv模块
-
从UNet网络中可以看出,不管是下采样过程还是上采样过程,每一层都会连续进行两次卷积操作,这种操作在UNet网络中重复很多次,可以单独写一个DoubleConv模块
- 如下图所示,in_channels设为1,out_channels为64。
- 输入图片大小为572×572,经过步长为1,padding为0的3×3卷积(
注意原文没有进行填充),因此得到feature map为570×570,而非572×572,再经过一次卷积得到568×568的feature map。
import torch.nn as nn class DoubleConv(nn.Module): """(convolution => [BN] => ReLU) * 2""" def __init__(self, in_channels, out_channels): super().__init__() self.double_conv = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=0), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True), nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=0), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True) ) def forward(self, x): return self.double_conv(x)

1.2.2 Down模块
UNet网络一共有4次下采样过程,模块化代码如下:
- Down模块先进行一个最大化池化,将高宽减半
- 然后接一个DoubleConv模块,让通道加倍
- 至此,UNet网络的左半部分的下采样过程的代码都写好了,接下来是右半部分的上采样过程。
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)

1.2.3 Up模块
- Up模块除了常规的上采样操作,还有进行特征的融合。
- UP模块定义了两种方法:Upsample和ConvTranspose2d,即双线性插值和反卷积。
- 在forward前向传播函数中,x1接收的是上采样的数据,x2接收的是特征融合的数据。特征融合方法就是先对小的feature map进行padding,再进行concat。
注意:在下面代码中,上采样后会进行padding,这点和原论文中不一样。
class Up(nn.Module):
def __init__(self, in_channels, out_channels, bilinear=True):
super(Up, self).__init__()
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:
x1 = self.up(x1)
# [N, C, H, W]
diff_y = x2.size()[2] - x1.size()[2]
diff_x = x2.size()[3] - x1.size()[3]
# padding_left, padding_right, padding_top, padding_bottom
x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,
diff_y // 2, diff_y - diff_y // 2])
x = torch.cat([x2, x1], dim=1)
x = self.conv(x)
return x
1.2.4 OutConv模块
-
用上述的DoubleConv模块、Down模块、Up模块就可以拼出UNet的主体网络结构了。
-
UNet网络的输出需要根据分割数量,整合输出通道。
-
下图展示的是分类为2的情况

class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
1.2.5 UNet网络构建
import torch
import torch.nn as nn
import torch.nn.functional as F
# pip install torchinfo
from torchinfo import summary
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=False):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 1024)
self.up1 = Up(1024, 512, bilinear)
self.up2 = Up(512, 256, bilinear)
self.up3 = Up(256, 128, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
if __name__ == '__main__':
net = UNet(n_channels=1, n_classes=1)
summary(model=net, input_size=(1, 1, 572, 572))
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
UNet [1, 1, 564, 564] --
├─DoubleConv: 1-1 [1, 64, 568, 568] --
│ └─Sequential: 2-1 [1, 64, 568, 568] --
│ │ └─Conv2d: 3-1 [1, 64, 570, 570] 640
│ │ └─BatchNorm2d: 3-2 [1, 64, 570, 570] 128
│ │ └─ReLU: 3-3 [1, 64, 570, 570] --
│ │ └─Conv2d: 3-4 [1, 64, 568, 568] 36,928
│ │ └─BatchNorm2d: 3-5 [1, 64, 568, 568] 128
│ │ └─ReLU: 3-6 [1, 64, 568, 568] --
├─Down: 1-2 [1, 128, 280, 280] --
│ └─Sequential: 2-2 [1, 128, 280, 280] --
│ │ └─MaxPool2d: 3-7 [1, 64, 284, 284] --
│ │ └─DoubleConv: 3-8 [1, 128, 280, 280] 221,952
├─Down: 1-3 [1, 256, 136, 136] --
│ └─Sequential: 2-3 [1, 256, 136, 136] --
│ │ └─MaxPool2d: 3-9 [1, 128, 140, 140] --
│ │ └─DoubleConv: 3-10 [1, 256, 136, 136] 886,272
├─Down: 1-4 [1, 512, 64, 64] --
│ └─Sequential: 2-4 [1, 512, 64, 64] --
│ │ └─MaxPool2d: 3-11 [1, 256, 68, 68] --
│ │ └─DoubleConv: 3-12 [1, 512, 64, 64] 3,542,016
├─Down: 1-5 [1, 1024, 28, 28] --
│ └─Sequential: 2-5 [1, 1024, 28, 28] --
│ │ └─MaxPool2d: 3-13 [1, 512, 32, 32] --
│ │ └─DoubleConv: 3-14 [1, 1024, 28, 28] 14,161,920
├─Up: 1-6 [1, 512, 60, 60] --
│ └─ConvTranspose2d: 2-6 [1, 512, 56, 56] 2,097,664
│ └─DoubleConv: 2-7 [1, 512, 60, 60] --
│ │ └─Sequential: 3-15 [1, 512, 60, 60] 7,080,960
├─Up: 1-7 [1, 256, 132, 132] --
│ └─ConvTranspose2d: 2-8 [1, 256, 120, 120] 524,544
│ └─DoubleConv: 2-9 [1, 256, 132, 132] --
│ │ └─Sequential: 3-16 [1, 256, 132, 132] 1,771,008
├─Up: 1-8 [1, 128, 276, 276] --
│ └─ConvTranspose2d: 2-10 [1, 128, 264, 264] 131,200
│ └─DoubleConv: 2-11 [1, 128, 276, 276] --
│ │ └─Sequential: 3-17 [1, 128, 276, 276] 443,136
├─Up: 1-9 [1, 64, 564, 564] --
│ └─ConvTranspose2d: 2-12 [1, 64, 552, 552] 32,832
│ └─DoubleConv: 2-13 [1, 64, 564, 564] --
│ │ └─Sequential: 3-18 [1, 64, 564, 564] 110,976
├─OutConv: 1-10 [1, 1, 564, 564] --
│ └─Conv2d: 2-14 [1, 1, 564, 564] 65
===============================================================================================
Total params: 31,042,369
Trainable params: 31,042,369
Non-trainable params: 0
Total mult-adds (G): 233.39
===============================================================================================
Input size (MB): 1.31
Forward/backward pass size (MB): 2683.30
Params size (MB): 124.17
Estimated Total Size (MB): 2808.78
===============================================================================================
2 针对UNet模型结构的改进
2.1 和transformers结合

2.2 概率设计

2.3 丰富表示增强

2.4 主干设计增强

2.5 跳层连接增强
注:U-Net++作者在知乎上曾经分享了他改造U-Net的思路,讲的非常细致,推荐大家阅读一下:
研习U-Net

2.6 bottleneck增强

以上改进总结来自这篇综述,感兴趣的可以参考:Medical Image Segmentation Review: The success of U-Net

为开发者提供按需使用的算力基础设施。
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)