
如何创建自定义模板的Severless服务
智灵如何创建自定义模板的Severless服务
原始需求
在这个示例中,我们将展示如何使用自定义模板来创建一个Serverless应用程序。假设一个如下的需求,有一家AI图像公司的提供商, 他们的客户是一些图像处理的设计师。 客户们需要一个服务,可以输入一些简单的提示词,这个服务能为设计师客户生成一个和提示词相关的图像,以方便做后续的加工和处理,提升设计师的工作效率。
设计分析
为了实现这样的工作,先需要做一个简单设计。首先需要一个Serverless,它能够接受一个简单的提示词,然后调用一个AI模型(Stable Diffusion),生成一个图像,并结果返回给请求方
那么首选的加载模型和执行模型推理的库,可以选择 huggingface 的 diffusers 库来完成。 用户的输入可以是如下先设计成如下的三个要素:
- 提示词:用于描述生成图像的内容
- 图像大小:生成图像的大小(长和宽, 默认 768 × 768)
- 推理步数:生成图像的需要的推理步数 (默认20步)
为了保证推理的生成的图片的质量我们选择了 SDXL的基础模型。 这样我们可以在不损失质量的情况下,生成最大1024×1024的高质量图像。
另外因为只是一个演示,所以我们会简单的使用同步方式返回图片内容。 为了方便图片的传输,我们会使用base64的方式返回图片。
效果原型
最终会有如下的一个效果和原型,如图:

这个界面中, 我们需要输入Serverless ID, 密钥和提示词就可以生成一张好看的图片。 是不是很简单啊,下面我们将一步一步的实现这个效果。跟着我们的步骤,你可以快速的了解如何使用Serverless Framework来实现一个自定义的Serverless应用程序。
步骤一:编写程序代码
如果实现这个需求, 我们可以使用Python来实现, 目前智灵平台提供的框架也是只有Python语言的,未来我们会增加更多的语言支持。
首先你需要阅读我们的关于如何使用Python来编写Serverless应用程序的文档和API, 开发接口非常简单,我们提供例子代码, 你可以根据我们提供的样列代码进行修改。 我们的样列代码在github上,你可以通过这里点击查看。
相关的手册文档可以参考这里
在认真阅读完我们的文档和例子,我们就可以开始来写代码了。
注意: 这个例子中的完整代码,我们都放到Github上了, 你可以点击这里查看。
先看第一段代码
python
# 导入必要的类库
import torch
from spirit_gpu import start, Env
from diffusers import DiffusionPipeline
from typing import Dict, Any
# 通过 diffusers 库加载本地模型, 我们将模型预先下载到本地,这样可以加快模型的加载速度
pipe = DiffusionPipeline.from_pretrained("/workspace/sdxl-base", force_download=False, torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
# 将模型加载到GPU上
pipe.to("cuda")1
2
3
4
5
6
7
8
9
10
这一段代码是在Serverless 启动阶段运行, 并不是在请求到来时候运行。 这样可以加快模型的加载速度,提高服务的响应速度。
接下来我们看看请求到来时候的代码, 这段代码是在请求到来时候运行的。
python
def handler(request: Dict[str, Any], env: Env):
# 通过框架获取请求的输入参数
input = request.get("input")
# 调用 get_valid_value 函数,获取输入图片高度参数的值,如果没有输入参数或参数非法,则使用默认值
height = get_valid_value(request, "height", "768", lambda x: x > 512 and x <= 1024)
# 调用 get_valid_value 函数,获取输入图片宽度参数的值,如果没有输入参数或参数非法,则使用默认值
width = get_valid_value(request, "width", "768", lambda x: x > 512 and x <= 1024)
# 调用 get_valid_value 函数,获取输入图片推理步数参数的值,如果没有输入参数或参数非法,则使用默认值
num_inference_steps = get_valid_value(request, "num_inference_steps", "20", lambda x: x >= 4 and x <= 50)
# 获取输入的提示词
prompt = input.get("prompt")
# 调用 diffusers 库的 pipe 函数,生成图片
images = pipe(prompt=prompt,
height = height,
width = width,
num_inference_steps=num_inference_steps).images[0]
# 将图片转换成base64格式
base64_image = to_base64(images)
print(f"result len is {len(base64_image)}")
# 结果以Json 形式返回
result = '{"image": "%s"}' % base64_image
# 返回结果
return result
# 将函数注册到框架中, 以便每次请求到来时进行回调
start({"handler": handler })1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
这段代码的功能非常简单, 就是把框架传入的输入进行处理,并交给Diffusers 框架做模型推理生成图像。 代码中需要注意的是, handler 函数定义一定符合框架的规范, 框架会根据这个函数的定义来调用这个函数。一定要通过 start 函数注册这个函数,以便框架能够找到这个函数。
里面调用了一些辅助函数,比如 get_valid_value 和 to_base64 函数, 这些函数的实现如下:
python
# 将图片转换成base64格式
def to_base64(images: Image.Image):
import io
import base64
im = images.convert("RGB")
with io.BytesIO() as output:
im.save(output, format="PNG")
contents = output.getvalue()
return base64.b64encode(contents).decode("utf-8")
# 获取输入参数的值,如果没有输入参数或参数非法,则使用默认值
def get_valid_value(data: Dict, key: str, default_value: str, is_valid) -> int :
value = int(data.get(key, default_value))
if is_valid(value):
return value
return int(default_value)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
代码部分我们已经完成了,接下来我们需要将代码打成Docker镜像,然后上传到智灵平台。 并定义成一个模板以方便智灵平台的Serverless 服务进行调用。
步骤二:构建镜像
在这个步骤里面,我们主要完成几个事情:
-
编写Dockerfile和构建Docker镜像
-
登录中心库,并上传Docker镜像和定义模板
镜像仓库介绍
智灵平台为了能更快的启动Serverless 服务, 提供了一个本地的镜像仓库, 你可以将你的Docker镜像上传到智灵平台的镜像仓库,将模板和我们智灵平台镜像仓库的镜像关联, 然后在创建Serverless服务时,可以直接选择你此模板以达到快速启动的目的。
在而在智灵平台上, 系统会自动地为每个租户创建一个镜像仓库私有的项目。 这样当你上传镜像到镜像仓库时,镜像会上传也只能上传到你租户下的项目中。 所以就只有你的租户可以访问到这个镜像。
中心库的信息,可以通过智灵平台的左侧导航栏的“镜像仓库”菜单进入,如下图所示:
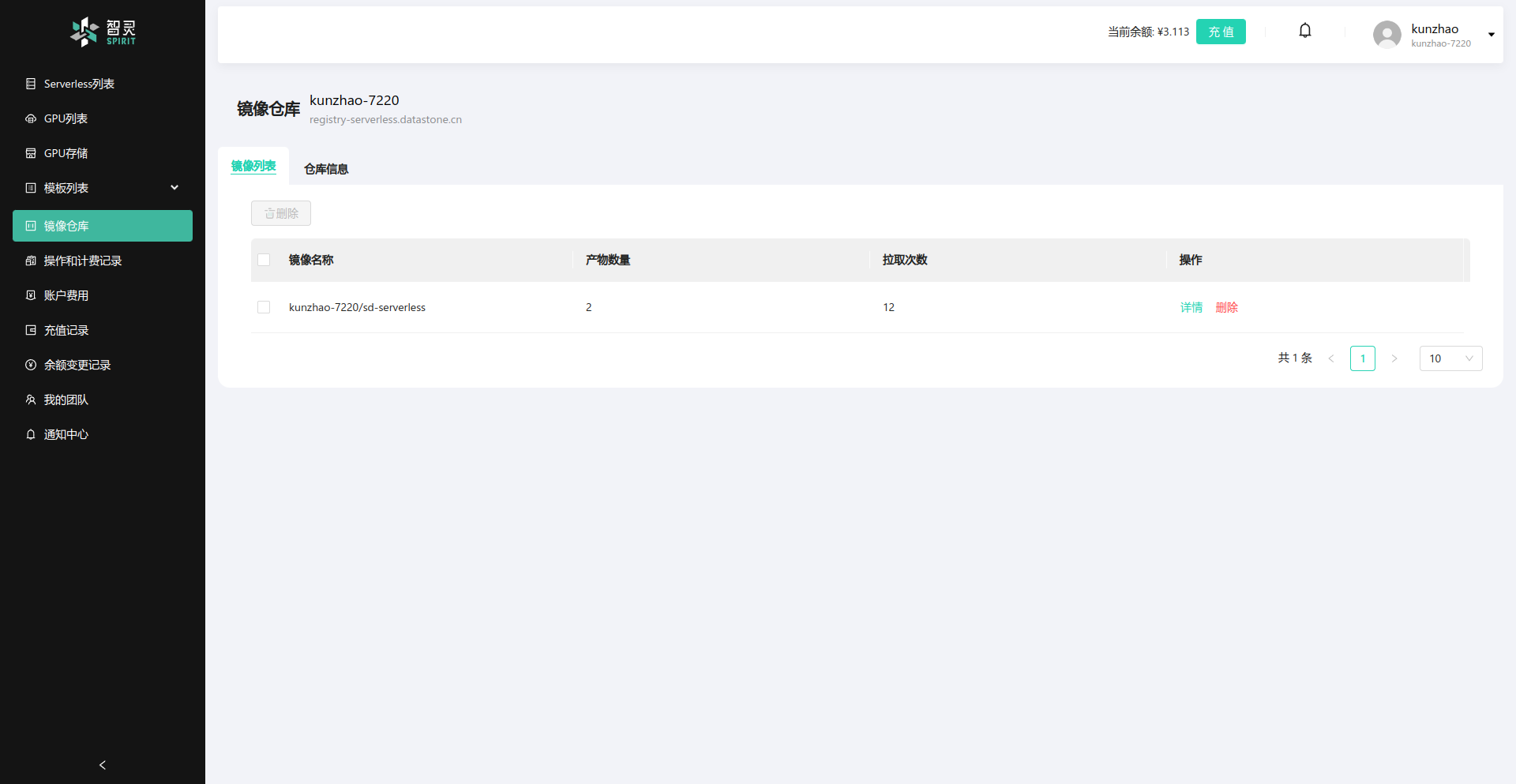
此图展示的是中心库的主界面,你可以看到你的项目列表,以及你的项目下的镜像列表。
如果要看镜像仓库相信信息,可以通过仓库信息 选项卡查看,如下图所示:
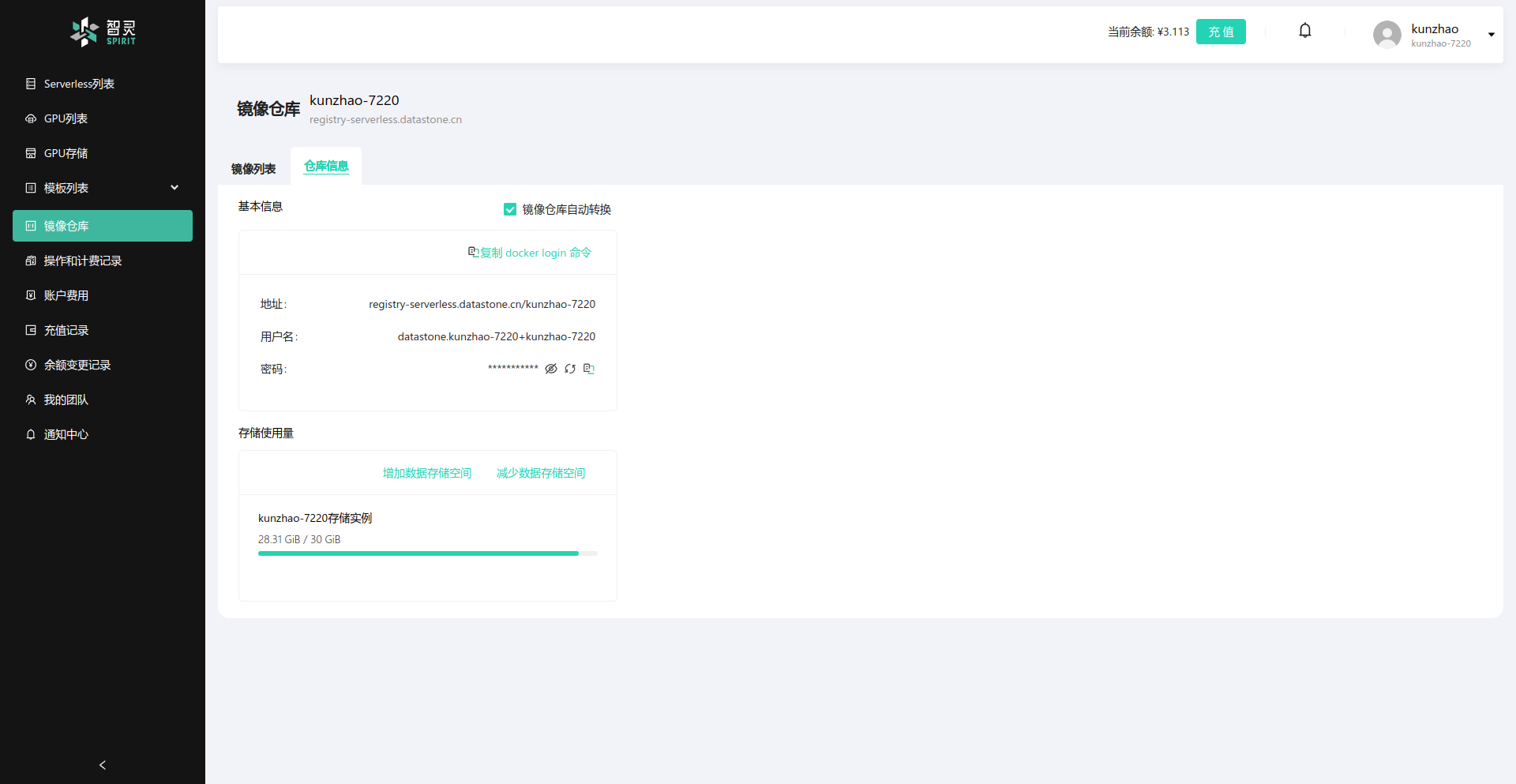
在仓库信息中,你可以看到你的仓库的地址,用户名和密码,以及你的项目的名称。你可以通过复制docker login命令 按钮来复制登录命令,然后在本地终端中执行这个命令,然后再复制密码来快速登录的镜像仓库,以方便你后面镜像构建完成后上传到镜像仓库。
注意, 系统默认免费赠送的中心仓库的大小是有限的,如果你的镜像超过了这个大小,你可以自行购买更多的存储空间。 目前智灵平台按照1GB空间,1天1分钱进行计费。 所以整体还是非常便宜的。
编写Dockerfile和构建Docker镜像
接下来,我们就需要开始编写我们的Dockerfile文件,以及构建我们的镜像了。
首先编写我们的Dockerfile
dockerfile
ARG BASE_URL
# 镜像构建的stage
FROM ${BASE_URL}/library/pytorch:2.1.0-py3.10-cuda11.8.0 AS builder
WORKDIR /workspace
# 准备依赖,创建虚拟环境
RUN python -m venv --system-site-packages /workspace/venv
# 复制依赖定义文件
COPY requirements.txt /workspace/
# 安装依赖
RUN /workspace/venv/bin/python -m pip install -r /workspace/requirements.txt
# 运行环境
FROM ${BASE_URL}/library/pytorch:2.1.0-py3.10-cuda11.8.0 AS v1
# 拷贝整个运行的虚拟环境以及依赖
COPY --from=builder /workspace/ /workspace
WORKDIR /workspace
# 拷贝SDXL的基础模型
COPY sdxl-base /workspace/sdxl-base
# 拷贝我们写好的Serverless代码
COPY src/ /workspace/src
# 设置环境变量
ENV PYTHONPATH /workspace/src
# 运行我们的Serverless代码
CMD ["/workspace/venv/bin/python", "-u", "/workspace/src/main.py"]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
此外,我们还需要使用docker-compose 的环境变量的特性来编译, 因此我们需要预装好docker-compose, 并且在docker-compose.yml文件中定义BASE_URL变量,如下所示:
yaml
# 构建的时候,需要提供两个环境变量, 一个是registry, 一个是tenant_name
# registry 是镜像仓库的地址, 一般是 registry-serverless.datastone.cn
# tenant_name 是你的租户名称。 可以通过镜像仓库里面信息看到。
services:
builder:
image: $registry/$tenant_name/sd-serverless:builder
build:
context: .
target: builder
args:
- BASE_URL=$registry
sd-serverless:
image: $registry/$tenant_name/sd-serverless:v1
build:
context: .
target: v1
args:
- BASE_URL=$registry1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
有了这两个文件, 我们还需要准备好我们的模型文件, 并把代码按照我们的Dockerfile要求的那样进行拜访。 具体的文件布局如下(样列):
.
├── compose.yml <- compose.yml 文件
├── Dockerfile <- dockerfile 文件
├── README.md
├── requirements.txt <- 源代码需要的依赖
├── sdxl-base <- SDXL的基础模型目录, 模型可以从网盘上下载
│ ├── model_index.json
│ ├── scheduler
│ ├── text_encoder
│ ├── text_encoder_2
│ ├── tokenizer
│ ├── tokenizer_2
│ ├── unet
│ ├── vae
│ └── vae_1_0
└── src
└── main.py <- 源代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
SDXL 的基础模型可以从智灵平台的网盘上下载,下载地址:
https://pan.baidu.com/s/11MTkqWRCHlVxACIw_UpZtQ?pwd=qs68
build时需要在compose.yml 文件所在的目录下执行如下的命令
shell
registry=registry-serverless.datastone.cn tenant_name=kunzhao-7220 docker compose build sd-serverless1
在这个命令执行时,我分别指定了registry 和 tenant_name 两个环境变量, 以方便在 compose.yml 文件中的变量替换。
build 构建完成后,我们就可以上传镜像到智灵平台的镜像仓库了, 通过如下命令进行上传:
shell
docker push registry-serverless.datastone.cn/kunzhao-7220/sd-serverless:v11
但是注意, 在上传之前, 你需要先登录到智灵平台的镜像仓库, 通过如下命令进行登录:
shell
docker login -u {登录名} registry-serverless.datastone.cn1
然后输入密码即可。
注意这个登录名和租户名有一定差异,建议通过智灵平台的镜像仓库菜单里面的仓库信息来查看你的登录名,通过
复制docker login命令按钮来复制登录命令,然后在本地终端中执行这个命令,然后再复制密码来快速登录的镜像仓库。 如下:
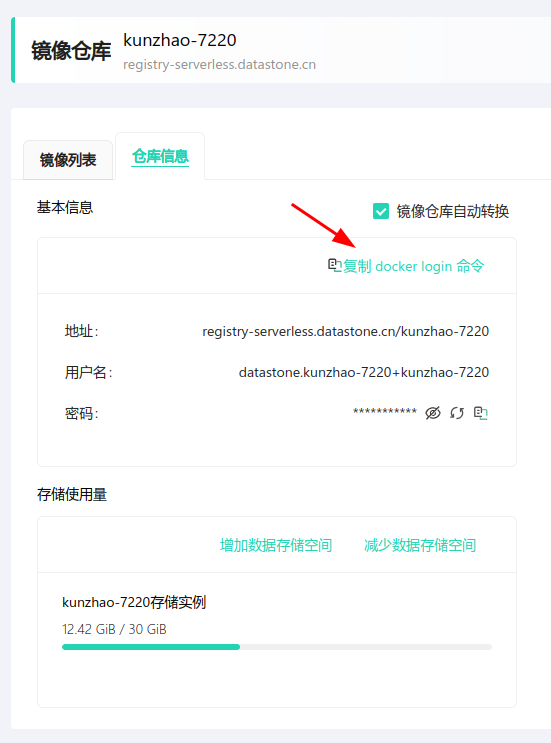
步骤三:上传镜像和定义模板
在我们上传镜像之前, 我们还需要先把模板定义好,因为模板里面有一些参数需要在第一次上传镜像前设置。我们通过 模板列表>Serverless 模板 > 新增模板 按钮,来定义一个新的模板: 在这个界面里面,最重要的信息有:
- 模板名称: 模板的唯一名称。
- 模板描述: 模板功能的描述。
- 镜像名称: 模板所对应的镜像的名称和Tag。
- 总是拉取最新镜像选项: 是否总是拉取最新的镜像, 这个选项在测试阶段比较有用,一旦到生产环境, 需要谨慎开启, 因为这个选项会导致每次启动服务都会拉取最新的镜像, 会增加服务启动的时间。
- 启用快速启动选项: 平台提供的镜像快速启动功能, 一但这个功能启用,会加速镜像的启动, 缩短服务的启动时间。但是这个功能依赖于镜像的转换,一单这个选项开启。 镜像上传后, 会进行自动转换成快速启动的镜像格式。这个格式会额外的占用更多的空间。 且第一次转换会比较费时。一旦转换完成后,可以大大提供镜像启动的速度。
- 环境变量: 模板启动时带入的环境变量。 可以将模板需要的环境变量在这里设置, 以方便后续的服务启动。
- 启动命令:启动命令可以覆盖镜像内的启动命令。如果镜像内已经有启动命令,那这里可以设置为空。
这些信息都是模板的重要参数,要根据你的实际情况来填写。并了解每个参数的实际用途。目前模板的填写的信息如下:
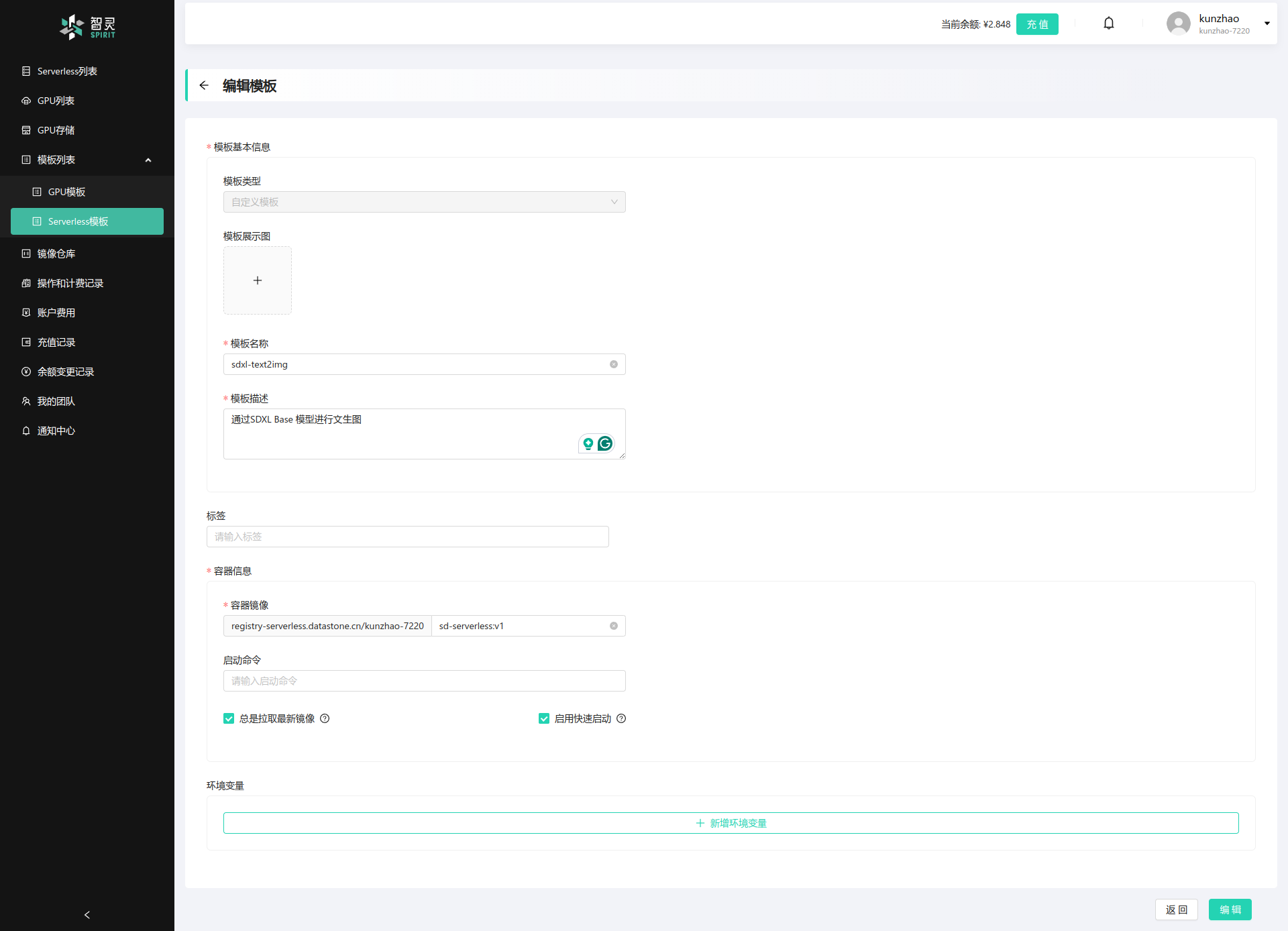
填写好模板信息后,我们就可以上传镜像了。 镜像上传就是使用docker push 命令, 我们已经在前一章节中做过了介绍,这里就不再赘述。
步骤四:创建Serverless服务
接下来就又到了我们喜闻乐见的创建Serverless 服务的时间, 我们在第一篇快速入门的文章里面有过详细的描述, 我们这里就不再赘述了。 这里将重点介绍我们这个Serverless服务的具体的配置选项。
我们的配置如图:
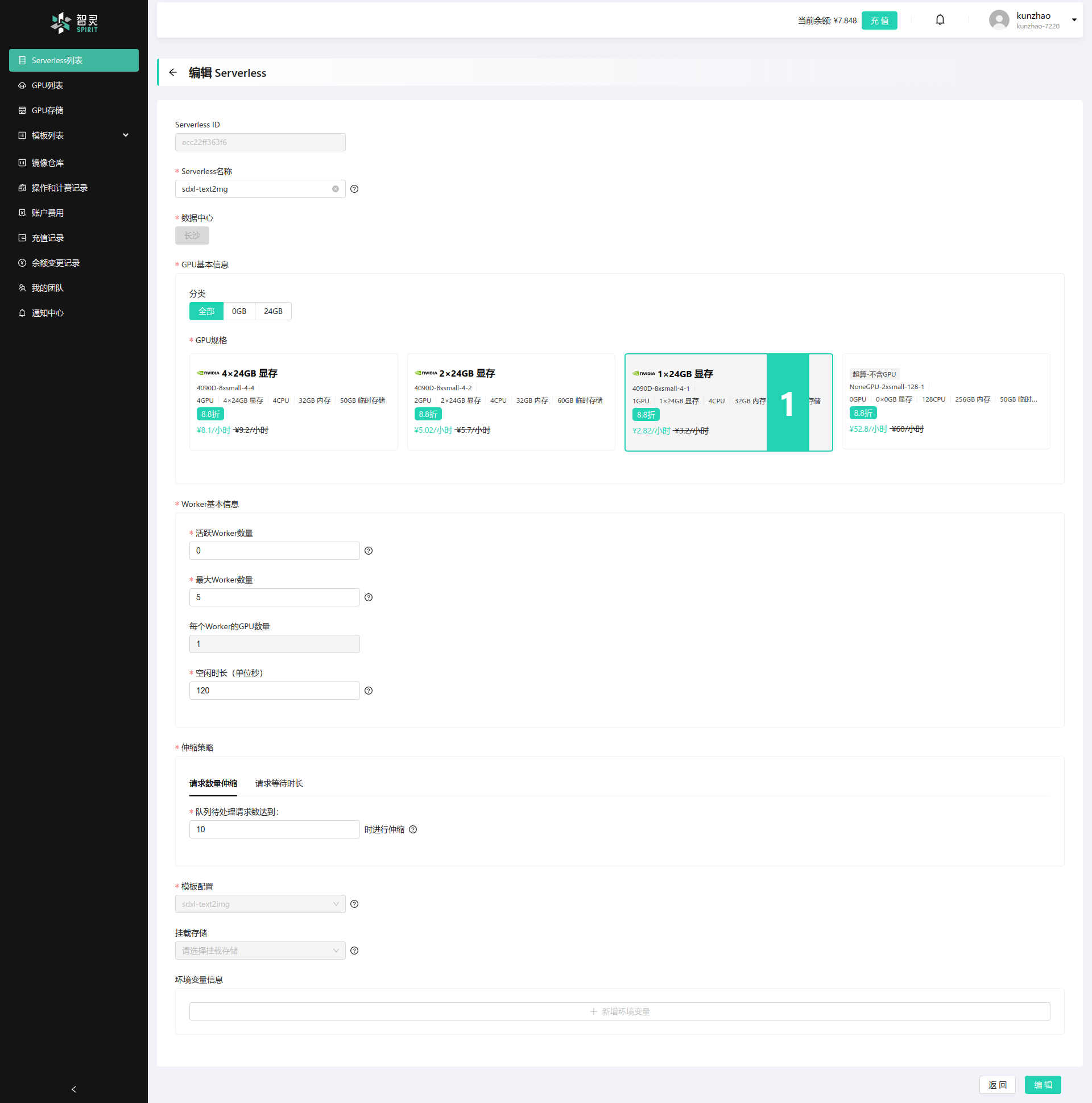
- serverless 名称:我们设置为 sdxl-text2img
- GPU的规格: 我们选择4090D 24GB。
- Worker数量: 活跃Worker数量为0, 这样我们在没有请求的时候就不需要出任何的费用。最大的Worker数量为5, 空闲时长我们设置为120秒。因为我们这个处理还是比较快, 120s保证能够处理完毕。
- 模板: 我们选择了我们刚刚定义的模板sdxl-text2img模板。
- 扩缩容的策略,我们选择按请求数量扩缩容策略, 并设置为10。
按照第一篇快速入门的文章, 我们同样的生成好Serverless 的 API Key。 我们需要记录下我们的Serverless ID和Serverless API Key接下来,我们就要开始编写我们的前端的代码了。
步骤五:编写前端代码
如文章开头描述的那样, 为了简化我们的Demo, 我们选择原生的HTML来实现我们的前端。 界面的元素非常简单, 我们只需要三个输入框, 一个按钮。后面如果你感兴趣可以在我的代码上加上更多的功能, 比如生成更多不同尺寸的图片,加上反向提示词等等。 在这里,三个输入框分别是:
- Serverless ID: 输入我们的Serverless ID, 用于调用我们的Serverless服务。
- Serverless API Key: 输入我们的Serverless API Key, 用于调用我们的Serverless服务。
- 提示词:输入图片生成的正向提示词。
- 发送按钮:发送请求Serverless
对于结果,我们用一个img 标签来展示图片。 整个HTML代码如下:
html
<!DOCTYPE html>
<html>
<head>
<title>Client</title>
<style>
input {
width: 600px;
padding: 2px;
margin: 5px 0;
box-sizing: border-box;
}
textarea {
width: 600px;
height: 100px;
padding: 2px;
margin: 5px 0;
box-sizing: border-box;
resize: none;
}
.status {
display: none;
height: 40px;
width: 40px;
margin-left: 30px;
}
</style>
<script src="client.js"></script>
</head>
<body>
<div id="app">
<h1>StableDiffusion XL Serverless Client Demo</h1>
<div><input id="serverlessID" type="text" value="" placeholder="input the serverlessId"/></div>
<div> <input id="apiSecret" type="password" value="" placeholder="input the apiSecret"/> </div>
<div> <textarea id="prompt" v-model="response" placeholder="Response" id="prompt", aria-placeholder="input the prompt" >a cute puppy</textarea> </div>
<button onClick="queuePrompt()">Send Request</button>
</div>
<div style="height: 60px; align-content: center;"> <span id="message"></span><img id="status" class=status src="assets/loading.gif" /></div>
<div width="1024", height="1024">
<img id="result" src="" />
</div>
</html>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
client.js 文件是用来处理前端的逻辑的, 这个文件的内容如下:
javascript
queuePrompt = async () => {
console.log("sending request")
const serverlessID = document.getElementById('serverlessID').value;
const apiSecret = document.getElementById('apiSecret').value;
const prompt = document.getElementById('prompt').value;
if (serverlessID == "" || apiSecret == "" || prompt == "") {
document.getElementById('message').innerText = "请填写所有字段"
return
}
document.getElementById('message').innerText = "计算中....."
statusElem = document.getElementById('status')
statusElem.style.display = "inline-block"
const response = await fetch(`https://api-serverless.datastone.cn/v1/${serverlessID}/sync`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${apiSecret}`
},
body: JSON.stringify({
input: { prompt }
})
});
// display the inferencing message in the label
const data = await response.json();
statusElem.style.display = "none"
image = JSON.parse(data);
document.getElementById('status').setAttribute("style", "display: none;")
document.getElementById('message').innerText = "结果:"
document.getElementById('result').src = "data:image/png;base64, " + image.image;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
这个代码的实现也非常的简单,就是读取html上输入内容, 并通过fetch函数来发送请求,然后将返回的结果显示在img标签中。
步骤六:测试
好了,一切准备就绪, 我们所要做的只是打开我们的html文件, 输入我们的Serverless ID和API Key, 输入我们的提示词, 然后点击发送按钮, 就可以看到我们的图片了。
如下图:
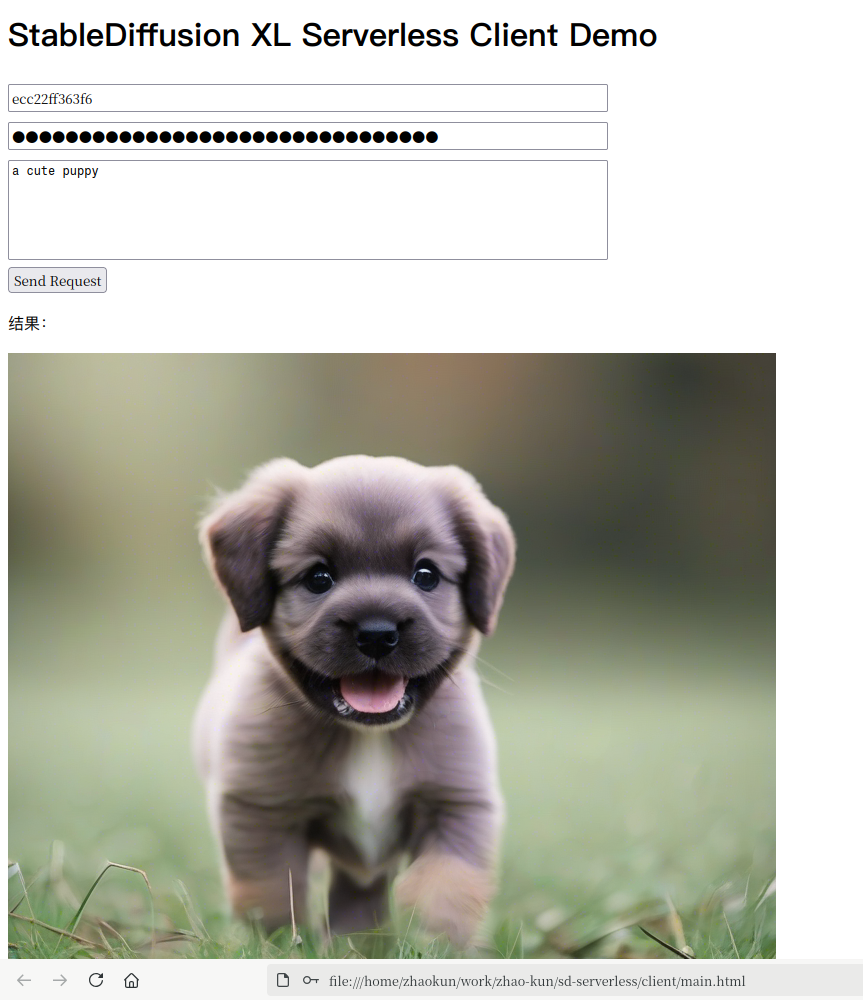
完整代码
整个项目的完整代码在 GitHub - datastone-spirit/sdxl-serverless-example 这里,大家可以自行下载测试

为开发者提供按需使用的算力基础设施。
更多推荐



 19
19 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)